Chapter 1
Introduction
SW is a many-faced entity, a colossal structure of standards and resources. It is also an idea shared by a multitude of communities, a concept of structured information, and an abstraction of knowledge. It is a mixture of technologies, created over a decade of work by professionals. Academia researches it, businesses try to create common ground with it, and visionaries preach of its promises; A richer world, where computer-driven agents find, process, and act upon information tailored for our need.
At the center of the SW we have the W3C, led by Tim Berners-Lee. Berners-Lee is perhaps more famous for his invention, the WWW, and he is also the one who coined the phrase SW. It is in his writings of Design Issues we find the essence of SW, namely the sentence "The Semantic Web is a web of data, in some ways like a global database" [5].
The web of data has been in the making since the late 1990s, but in terms of traction there is still much to be done. Some complain it is still very much an academic affair, while others complain of the lack of interest from the developing community.
This master thesis has taken the approach to look at the gap between SW and the developing community by trying to construct a framework that offers tools to access SW. It has been written in and for JS, as it is a programming language of the web, and the timing seems right.
JS can relate to SWs struggles for traction. For long time it was ridiculed by developers, saying it was a silly language that merely created fancy effects on web pages, but not doing anything useful. Douglas Crockford, an evangelist of JS, has called JS the world's most misunderstood language [15]. And if the name and its syntax was not confusing enough, the browsers with their differing implementations were not making it any easier.
There were, and still are, many reasons to why people get confused by JS. But in the mid-2000s, efforts were made to make JS more accessible to developers. Prototype, MooTools, and jQuery are all frameworks that promises APIs for easier, cross-browser access to the power within JS. And it worked! Readily manipulation of the DOM, asynchronous fetching of resources with AJAX, and the increasing efforts of making JS into a full-fledged server-side programming language, are making JS a powerful and fun tool for developers to work with.
It is this fertile ground the work of this master thesis is trying to tap into. This work presents Graphite, which is the authors main contribution. It is an AMD-based framework (described in section 2.2.8.3) written in JS that sports a modularized API to fetch resources in the SW, process it and output in useful way for JS-developers. Frameworks typically serve to implement (larger-scale) components, and are implemented using (smaller-scale) classes [31]. This description of frameworks suits my implementation well, as the work in large part will consist of defining smaller components and have them collaborate effectively for a higher-level purpose.
This master thesis will describe the work and choices made during the implementation of Graphite. It is divided into three parts. The first consists of the underlying theory and constraints in technology (chapter 2), and how this fits into the scope of this thesis (chapter 3). The second part describes the implementation, and starts by explaining which tools and third party libraries I made use of (chapter 4 and 5 respectively). It continues with an extensive presentation of the framework itself (chapter 6) and a demo I constructed to demonstrate some of the frameworks' capabilities (chapter 7). Finally, in the third part I offer a discussion of the work (chapter 8), and a conclusion of the matter (chapter 9).
I hope to contribute to the developing community of SW and JS in two ways; through the thesis, to showcase what is already available and present some research and thoughts of my own, and through the framework, in the hopes that it contributes to the evolution of handling SW in JS.
Part 1
Foundations
Chapter 2
Background
This chapter will describe the technologies, standards, and theories that Graphite has been build upon.
2.1 SW
SW represents a multitude of standards and technologies, and seeing the whole picture may not be so easy to grasp. A perhaps fitting metaphor is the story of the elephant and the blind men. It is a story made famous by the poet John Godfrey Saxe, and tells the story of how six men tried to describe an elephant. Depending on which part they touched, each described the elephant differently. One approached its side, and called it a wall. Another touched the tusk, and surely it had to be a spear. The third took hold of the trunk, and spoke of how it resembled a snake. The fourth reached out for its knee, and stated it had to be like a tree. The fifth touched the ear, and meant it had to be like a fan. Finally, the last one had grabbed its tail, and stated how it had to be like a rope [34].
In comparison, here are some of the descriptions we have of SW:
- A web of data [5].
- An extension of WWW [25].
- A killer app [9].
- W3C's vision of the Web of linked data [50].
The list above are some of the descriptions in literature, and they are all true. Other aspects of SW is the set of standards it sports (e.g. RDF, RDFS, OWL, and SPARQL), technological foundations (e.g. LD), applicabilities (e.g. use of LOD amongst governments), social consequences (democratizing data), limitations (e.g. AAA), and more.
2.1.1 RDF
At the heart of SW lies RDF. It is a formalized data model that asserts information with statements that together naturally form a directed graph. Each statement consists of one subject, one predicate, and one object, and are hence often called a triple. The three elements have meanings that are analogous to their meaning in normal English grammar[24,p. 68-69], i.e. the subject in a statement is the entity which that statement states something about.
As an example of statements, take the following:
- Arne knows Kjetil.
- Arne has last name Hassel.
These statements are represented as a graph in figure 2.1. It illustrates that the subject "Arne" is related to the object "Kjetil" by the predicate "knows", and to the object "Hassel" by the predicate "familyName".
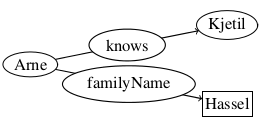
You might have noticed that the two objects have different shapes, one being a circle (like the subject), and the other being a rectangle. That is to show that "Hassel" is a literal. Literals are concrete data values, like numbers and strings, and cannot be the subjects of statements, only the objects[24,p. 69].
The circles on the other hand, are known as resources, and can represent anything that can be named. As RDF is optimized for distribution of data on WWW, the resources are represented with IRIs (IRI is an extension of URI, and is explained in section 2.1.4.2).
IRIs are usually declared into namespaces, to make terms more human-readable (e.g. resources in the namespace http://example.org/ could be prefixed ex). If we look at figure 2.1, we have two resources, namely Arne and Kjetil. To make these available as LD, we could assign them into the namespace ex, writing them respectively as ex:Arne and ex:Kjetil.
The basic syntax in RDF has a relatively minimal set of terms. It enables typing, reification, various types of containers (bags, sequences, and alternatives), and assigning of language or data type to a literal [2]. Its power lies in its extensibility by URI-based vocabularies [26]. By sharing vocabularies as standards between software applications, you can easier exchange data.
With this in mind, we see that figure 2.1 is faulty, and we turn to figure 2.2 to see a correct representation (using the vocabulary FOAF, prefixed foaf, for the properties).
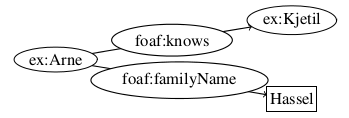
Not all resources are given IRIs though. The exception to the rule are BNs, which represent resources that have no separate form of identification [26], either because they cannot be named, or it is neither possible nor necessary at the time of modeling. These resources are not designed to link data, but to model relations of resources that are given IRIs.
An example of modeling BN is given in figure 2.3, where I have modeled that ex:Arne has a friend, who we do not know anything about except his nicknames, Bjarne and Buddy.
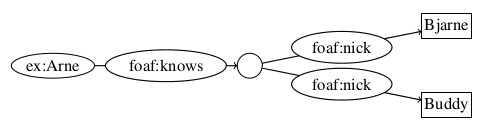
The figures 2.2 and 2.3 are examples of the form of visualization we will have of graphs in RDF.
2.1.2 RDFS
RDFS is an extension in form of vocabulary that extends the semantic expressiveness of RDF. But RDFS is not a vocabulary in the traditional sense that it covers any topic-specific domain [25,p. 46]. It is designed to extend the semantic capabilities of RDF, and in that sense it can be regarded as a meta-vocabulary.
The perhaps most important feature of RDFS is its ability to support taxonomies. It empowers the use of rdf:type by introducing rdfs:Class, in effect enabling classification. The properties rdfs:range, rdfs:domain, rdfs:subClassOf, and rdfs:subPropertyOf further extends this feature.
It also builds on the reification-properties of RDF, by instantiating rdf:Statement as a rdfs:Class. It continues by clarifying the semantics of rdf:subject, rdf:predicate, and rdf:object by instantiating them as rdf:Property, and in terms of entailment (explained in section 2.1.7) ties together with rdfs:range and rdfs:domain.
Another extension is the clarification of containers by introducing the class rdfs:Container and the property rdfs:containerMembershipProperty, which is an rdfs:subPropertyOf of the rdfs:member [13].
Finally, it introduces the utility properties rdfs:seeAlso and rdfs:isDefinedBy. The former represents resources that might provide additional information about the subject resource, while the latter gives the resource which defines a given subject. It also clarifies the use of rdf:value, to encourage its use in common idioms [13].
2.1.3 OWL
In the same way RDFS is an extension to RDF in order to express richer semantics, OWL is an extension to RDFS to express even richer semantics. It does so by introducing vocabularies that are based on formal logic, and aims to describe relations between classes (e.g. disjointness), cardinality (e.g. "exactly one"), equality, richer type of properties, characteristics of properties (e.g. symmetry), and enumerated classes [44,sec. 1.2].
As of this writing, OWL exists in two versions: The version recommended by W3C in 2004 (often known as OWL 1), and OWL 2, which became recommended in 2009. OWL 2 is an extension and revision of OWL 1, and is backward compatible for all intents and purposes [46].
OWL 1 features three sublanguages/profiles1. These are, with complexity in increasing order (all quoted from OWL Features [44]):
- OWL Lite: Supports classification hierarchy and simple constraints (e.g. only cardinality values of 0 and 1).
- OWL DL: Maximum expressiveness while retaining computational completeness and decidability.
- OWL Full: Maximum expressiveness and the full syntactic freedom of RDF, but with no computational guarantees.
OWL 2 also make a distinction with DL and Full. It does not list a Lite profile, but all OWL Lite ontologies are OWL 2 ontologies, so OWL Lite can be viewed as a profile of OWL 2 [47]. In addition, DL has three sublanguages that are not disjunct, and also does not cover the complete OWL 2 DL. These sublanguages are (all quoted from OWL 2 Profiles[47]):
- OWL EL: Designed to be used with ontologies that contain very large numbers of either properties or classes.
- OWL QL: Aimed at applications that use very large volumes of instance data, and where query answering is the most important reasoning task.
- OWL RL: Aimed at applications that require scalable reasoning without sacrificing too much expressive power.
To go through all differences between OWL 1 and OWL 2 would be beyond the scope of this thesis, but suffice to say is that OWL 2 is designed to be backward compatible with OWL 1, and the sublanguages OWL provides as a whole increases the reasoning capabilities of SW.
2.1.4 LD
A cornerstone of RDF is that all identifications (that is, except BNs) are IRIs. In this way, machines can browse the web for relevant resources, much like you browse the web through hyperlinks. This design feature makes RDF adhere to LD, which is a term that refers to a set of best practices for publishing and connecting structured data on the web [12].
Tim Berners-Lee have in his article about LD2 outlined four "rules" for publishing data on WWW [7]:
- Use URIs as names for things.
- Use HTTP URIs so that people can look up those names.
- When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL).
- Include links to other URIs, so that they can discover more things.
These have become known as the "Linked Data principles", and provide a basic recipe for publishing and connecting data using the infrastructure of the WWW while adhering to its architecture and standards [12].
LD are reliant on two web-technologies, namely IRIs and HTTP. Using the two of them you can fetch any resource addressed by an IRI that uses the HTTP-scheme. When combining this with RDF, LD builds on the general architecture of the Web [43].
The Web of Data can therefore be seen as an additional layer that is tightly interwoven with the classic document Web and has many of the same properties [12]:
- The Web of Data is generic and can contain any type of data.
- Anyone can publish data to the Web of Data.
- Data publishers are not constrained in choice of vocabularies with which to represent data.
- Entities are connected by RDF links, creating a global data graph that spans data sources and enables the discovery of new data sources.
2.1.4.1 LOD
Based on the notion of LD, there is a movement to publish data on WWW as LOD. Especially toward governmental institutions there is now an increasing trend of opening data3.
To encourage this trend, Tim Berners-Lee published a star rating system. On a scale from one to five stars, it rates how well the given dataset is in becoming open. It is incremental, meaning that the dataset needs to be have one star before it can be given two. One star is given if your data is available on WWW with an open license. Two stars means that your data is available in machine-readable structure, and is valid for another star if the structure is a non-proprietary format (e.g. CSV instead of Excel). Four stars are given if your the data is identified by using open standards from W3C (e.g. RDF and SPARQL). The last star means that your data also link to other people's data, in order to provide context [7].
Figure 2.4 shows the linking open data cloud diagram. It illustrates to some extent the magnitude of data that are linked as of yet4.
2.1.4.2 URL vs. URI vs. IRI
Throughout this thesis you will read the terms URLs, URIs, and IRIs being used interchangeably. I strive to use IRI as it is the term fronted in the newest specs by W3C, but in some cases it is more appropriate to use the others because of the texts they reference.
URLs and URIs are the most commonly used terms. The former denotes dereferenceable resources on WWW, while the latter is a generalization that can denote anything that can be identified, even resources not on WWW. But URIs are limited to the character-encoding scheme ASCII, and as such IRI has been introduced to solve this problem5.
URI have the form scheme:[//authority]path[?query][#fragment], where the parts in brackets are optional. The list below explains the different terms (shortened versions of the ones offered by Hitzler et.al. [25,p. 23]. The explanations are equally valid for URL and IRI.
- scheme: The scheme classify the type of URI, and may also provide additional information on how to handle URIs in applications.
- authority: An authority is the provider of content, and may provide user and port details (e.g. arne@semanticweb.com, semanticweb.com:80).
- path: The path is the main part of many URIs, though it is possible to use empty paths, e.g., in email addresses. Paths can be organized hierarchically using / as separator.
- query: The query can be recognized with the preceding ?, and are typically used for providing parameters.
- fragment: Fragments provide an additional level of identifying resources, and are recognized by the preceding #.
2.1.5 Serializations
RDF in itself offers no serialization of the graph it represents. But there are many serializations available, and more are coming as of this writing.
There are some considerations to take when choosing a serialization for a given project. One consideration is the ease for humans to read the syntax, which is very useful if you want to verify how your data is related. Another is the availability of tools to process the serialization. RDF/XML, for example, is based on XML, and as such there are many tools that can deserialize it. Turtle on the other hand is specific for RDF, and may not be as easy to deserialize. But most will agree that the latter is much easier to read and understand than the former.
2.1.5.1 RDF/XML
RDF/XML has been recommended by W3C to represent RDF since the beginning of SW [26,sec. 2.2.4]. As the name suggests, RDF/XML is based on the markup language XML. XML may not be as humanly accessible as some of the other serializations, but it is the most commonly used, probably because of the readily available software to process XML-documents.
XML is tree-based, which means some considerations need to be taken when we serialize graphs. Each statement will have the subject as the root, followed by the predicate, and then the object. As an example of this we have listing 2.5, which shows a serialization of figure 2.2.
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF xmlns:rdf ="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
<rdf:Description rdf:about="http://example.org/Arne">
<foaf:knows>
<rdf:Description rdf:about="http://example.org/Kjetil">
</rdf:Description>
</foaf:knows>
<foaf:familyName>Hassel</foaf:familyName>
</rdf:Description>
</rdf:RDF>
Another reason for XML being chosen as the default serialization was that it was readily available at the time RDF was being standardized. Figure 2.6 shows a timeline of the development of XML and SW.

Listing 2.5 shows that we have namespaces in XML through the attribute rdf:xmlns. But we cannot use namespaces in values given to attributes (i.e. we have to write rdf:about="http://example.org/Arne" instead of rdf:about="Arne"). This adds to the notion that XML-documents are bigger than what we need to serialize RDF.
2.1.5.2 Turtle
Turtle defines a textual syntax for RDF that allows RDF graphs to be completely written in compact and natural text form [3]. The latest version was submitted as a W3C Team Submission 28th of March 2011. Listing 2.7 shows the serialized form of figure 2.2.
@prefix ex: <http://example.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
ex:Arne foaf:knows ex:Kjetil ;
foaf:familyName "Hassel" .
We see from the example that IRIs are written with angular brackets, literals with quotation marks, and statements ends with either a semicolon or a period. The usage of semicolon is a syntactic sugar, and enables writing the following triples without their subject, as they reuse the subject in the first statement. We can also reuse the subject and the predicate in a statement by using the comma, in essence writing a list.
The syntax @prefix is also used in the listing. This allows us to introduce namespaces, and abbreviate IRIs by prefixing them (e.g. <"http://example.org/Arne"> → ex:Arne). We also have the term @base, which also enables us to abbreviate IRIs, by writing the suffix in angular brackets (e.g. @base <http://example.org/> → <Arne>).
Turtle also supports BNs by wrapping the statements in square brackets. Listing 2.8 shows all of these syntaxes in use by serializing figure 2.3.
@base <http://example.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<Arne> foaf:knows [
foaf:nick "Bjarne" , "Buddy" .
]
There is also syntactic sugar for writing collections. This is done by enveloping the resources as a comma-separated list in parentheses. Lastly, Turtle abbreviates common data types, e.g. the number forty two can be written 42, instead of "42"<http://www.w3.org/2001/XMLSchema\#integer>, and the boolean true can be written true instead of "true"<http://www.w3.org/2001/XMLSchema\#boolean>.
Turtle has become popular amongst the academic circles of SW, as it is a valuable educational tool because of its simplicity and readability.
2.1.5.3 N3
N3 is often presented as a compact and readable alternative to RDF/XML [8], but the syntax supports greater flexibility than the confinements of RDF (e.g. support for calculated entailment with "built-in" functions [6]).
It dates back to 1998 [25,p. 25], and currently holds status as a Team Submission at W3C, last updated 28th of March 2011. Figure 2.2 is serialized as N3 in listing 2.9.
@prefix ex: <http://example.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
ex:Arne foaf:knows ex:Kjetil ;
foaf:familyName "Hassel" .
N3 shares a lot of the syntax of Turtle, but is an extension in the regard that it has extra syntax (e.g. @keywords, @forAll, @forSome) [3,sec. 9].
2.1.5.4 N-Triples
N-Triples was designed to be a fixed subset of N3 [45,sec. 3]. It is also a subset of Turtle, in that Turtle adds syntax to N-Triples [3,sec. 8]. Serialization of figure 2.2 is given in listing 2.10.
<http://example.org/Arne> <http://xmlns.com/foaf/0.1/knows> <http://example.org/Kjetil> . <http://example.org/Arne> <http://xmlns.com/foaf/0.1/familyName> "Hassel" .
One way of looking at N-Triples is to see it as Turtle without the syntactic sugar.
2.1.5.5 RDF JSON
RDF JSON was one of the earliest attempts to make a serialization of RDF in JSON. It is designed as part of the Talis Platform6, and is a simple serialization of RDF into JSON. Figure 2.2 is serialized into RDF JSON in listing 2.11.
{
"http://example.org/Arne": {
"http://xmlns.com/foaf/0.1/knows": [ {
"value": "http://example.org/Kjetil",
"type": "uri"
} ],
"http://xmlns.com/foaf/0.1/familyName": [ {
"value": "Hassel",
"type": "literal"
} ]
}
}
RDF JSON uses the syntax provided by JSON (explained in section 2.2.4). All triples have the form { "S": { "P": [ O ] } }, where "S" is the subject, "P" is the predicate, and O is a JSON object with the following keys:
- type, required: either üri", "literal" or "bnode".
- value, required: the lexical value of the object.
- lang, optional: the language of the literal.
- datatype, optional: the data type of the literal.
2.1.5.6 JSON-LD
JSON-LD is another JSON based serialization of RDF, and is the newest serialization to be included by W3C. It became a working draft on 12th of July 20127, after being in the works for about a year by the JSON-LD CG8. It has been included in the work of the RDF WG in hope that it will become a W3C Recommendation that will be useful to the broader developer community9.
JSON-LD CG has from the start worked with the concern that RDF may be to complex for the JSON-community10, and as such has embraced LD rather than RDF. That being said, it is a goal that JSON-LD will serialize a RDF graph, if that is what the developer want to do. This is reflected in the current working draft, in that subjects, predicates and objects "SHOULD be labeled with an IRI". This does introduce the problem that valid JSON-LD documents may not be valid RDF serializations.
Another design goal of JSON-LD is simplicity, meaning that developers only need to know JSON and two keywords (i.e. @context and @id) to use the basic functionality of JSON-LD[49,sec. 2]. So how do we use these keywords? Lets look at two examples in listings 2.12 and 2.13, which serialize figures 2.2 and 2.3 respectively.
{
"@context": {
"ex": "http://example.org/",
"foaf": "http://xmlns.com/foaf/0.1/"
},
"@id": "ex:Arne",
"foaf:knows": "ex:Kjetil",
"foaf:familyName": "Hassel"
}
{
"@context": {
"ex": "http://example.org/",
"foaf": "http://xmlns.com/foaf/0.1/"
},
"@id": "ex:Arne",
"foaf:knows": {
"foaf:nick": [ "Bjarne", "Buddy" ]
}
}
In listing 2.12 we see that prefixing namespaces are featured in line 3 and 4. We also see that the subject are defined by using the proprety @id. The absence of @id creates a blank node, as shown in listing 2.13.
Another design goal of JSON-LD is to provide a mechanism that allow developers to specify context in a way that is out-of-band. The rationale behind this is to allow organizations that already have deployed large JSON-based infrastructure to add meaning to their JSON documents that is not disruptive to their day-to-day operations[49]. In practice this will work by having two JSON documents, one being the original JSON document, which is not linked, and another that provide rules as to how terms should be transformed into IRIs. Listing 2.14 shows how a serialization of figure 2.1 could be transformed into the serialization of figure 2.2.
// A non-LD JSON object
{
"Arne": {
"knows": "Kjetil",
"lastname": "Hassel"
}
}
// A JSON-LD object designed to transform the object above into a JSON-LD compliant object
{
"@context": {
"ex": "http://example.org/",
"foaf": "http://xmlns.com/foaf/0.1/",
"Arne": {
"@id": "ex:Arne"
},
"Kjetil": {
"@id": "ex:Kjetil"
},
"knows": "foaf:knows",
"lastname": "foaf:familyName"
}
}
2.1.5.7 RDFa
RDFa is another serialization that recently got promoted in the W3C-system. As of 7th of June 2012 it is a W3C Recommendation, and offers a range of documents (the RDFa Primer11, RDFa Core12, RDFa Lite13, XHTML+RDFa 1.114, and HTML5+RDFa 1.115).
RDFa makes it possible to embed metadata in markup languages (e.g. HTML), so as to make it easier for computers to extract important information. This is in response to the fact that some semantics may not be specific enough. Take the title-tags in HTML, H1-H6. Good practices suggest only using H1 one time, so that it only specifies the most important title for the page. But even so, what does the H1-tag specify title for? Is it the page as a whole, or is it the specific article on that page. With RDFa you can specify this.
The reasoning is that by making use of independently created vocabularies, the quality of metadata will increase. And by tying it into RDF, you can increase the overall knowledge of WWW.
RDFa has a syntax much to big to describe in detail here, but lets look at an example, by serializing figure 2.2 into a fracture of HTML, given in listing 2.15.
<div
vocab="http://example.org/"
prefix="foaf: http://xmlns.com/foaf/0.1/"
about="Arne">Arne knows
<span
property="foaf:knows"
resource="Kjetil">Kjetil</span>
and has last name <span
property="foaf:familyName">
Hassel</span>.</div>
Listing 2.15 shows us the use of the attributes vocab, prefix, about, property, and resource:
- vocab defines the usage of a single vocabulary for the nested terms.
- prefix allows us to introduce prefixes in case we want to mix in more vocabularies.
- about defines the subject in a triple.
- property defines the predicate in a triple.
- resource may define the object and the subject, depending on context.
2.1.6 Querying
An important feature of structured data is the possibility of querying it. You could have the users scour model in tools like a SW or RDF browser, but this can be a tedious task, and very inefficient for a machine. To query RDF we need a query language that recognizes RDF as the fundamental syntax [24,p. 192] (or rather, as the fundamental model).
2.1.6.1 SPARQL
SPARQL is the answer to the need for a query language. It exists as version 1.0, which became a W3C Recommendation 15th of January 2008, and as version 1.1, which is a working draft, last updated 5th of January 2012. Version 1.1 builds upon version 1.0, and sports features such as (all fetched from the document SPARQL 1.1 Query Language [48]):
- The query forms SELECT, ASK, CONSTRUCT, and DESCRIBE,
- Grouping, ordering, and limitation of results fetched,
- Several shortened query forms,
- Aggregation,
- Subqueries,
- Negation,
- Expressions in the SELECT clause and Property Paths,
- Assignment, and
- A large list of functions and operators.
As the most powerful version, I will use version 1.1 as the basis for this thesis, and it will be the version I refer to when referring to SPARQL.
There are four fundamental forms of read-queries in SPARQL, namely SELECT, ASK, CONSTRUCT, and DESCRIBE. The two latter returns new graphs, that can be used as basis for additional queries and manipulations (e.g. merging with other graphs).
The SELECT form enables us to query for variables, and return them in tabular form. We can project a specific list of variables we want returned, or just select all variables by using the asterisk sign.
Listing shows a very simple example of a SELECT query. If we use that query against the model in figure 2.2, we will get the table 2.1 as a result.
SELECT *
WHERE { ?subject ?predicate ?object }
| ?subject | ?predicate | ?object |
|---|---|---|
| http://example.org/Arne | http://xmlns.com/foaf/0.1/knows | http://example.org/Kjetil |
| http://example.org/Arne | http://xmlns.com/foaf/0.1/familyName | "Hassel" |
As we see from table 2.1, the query lists all triples we know in the model.
The ASK form enables us to verify whether or not certain query pattern are true or not. We could use it to ask if we know from the model in figure 2.2 whether or not there are an entity which has a given name Ärne". Listing 2.17 shows how this is done.
@prefix foaf: <http://xmlns.com/foaf/0.1/>
ASK { ?x foaf:givenName "Arne" }
In our case the result would be false.
The CONSTRUCT form enables us to derive a graph derived from other graphs. Lets look at another example in listing 2.18.
@prefix foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT { ?x foaf:givenName "Arne" }
WHERE { ?x foaf:familyName "Hassel" }
Now, if we were to run the ASK query in listing 2.17 against the new graph, we would get the result true. And if we ran the SELECT query in listing , we would get the result in table 2.2.
| ?subject | ?predicate | ?object |
|---|---|---|
| http://example.org/Arne | http://xmlns.com/foaf/0.1/givenName | "Arne" |
The DESCRIBE form results in a single RDF graph. It differs from the CONSTRUCT form in that we do not specify which triples we want the new graph to consist of, but rather that the SPARQL query processor determines which triples that are relevant. The relevant triples depend on the data available in the graph(s) queried, but takes basis in the resource(s) identified in the query pattern.
Lets look at the query in listing 2.19, which we apply to the models in figures 2.2 and 2.3, which we have assigned to IRIs http://example.org/GraphA and http://example.org/GraphB respectively. The result could be something like the serialization shown in listing 2.20.
@prefix foaf: <http://xmlns.com/foaf/0.1/>
@prefix ex: <http://example.org/>
CONSTRUCT ?y
FROM <http://example.org/GraphA>
FROM NAMED <http://example.org/GraphB>
WHERE { ?x foaf:knows ?y }
@prefix foaf: <http://xmlns.com/foaf/0.1/> . [ foaf:nick "Bjarne" , "Buddy" . ]
The resulting graph has two triples, namely the one concerning the entity which we known has the nicks "Bjarne" and "Buddy". As there are no triples where http://example.org/Kjetil acts as the subject, we can not describe anything.
I have introduced the token FROM in the query. This syntax allows us to specify which RDF Datasets we wish to query. This syntax is optional, as the query processor will use the default graph if nothing is specified. There can be one default graph, whose IRI we override if we specify FROM without NAMED. A query can take any number (or none) of named graphs, but do not need a default graph if we have one or more named graphs.
SPARQL has a great number of features, and I can not describe them all here16. But suffice to say, SPARQL is a powerful language that enables us to ask a variety of questions regarding our data.
2.1.6.2 SPARQL Update Language
The SPARQL 1.1 specification is part of a set of documents, which comprises ten documents. One of these is the document regarding SPARQL Update Language. It introduces an extension of the SPARQL syntax that allow us to update RDF datasets. The tokens are divided into two groups, Graph Update and Graph Management. The former consists of INSERT DATA, DELETE DATA, DELETE/INSERT (with the shortcut form DELETE WHERE), LOAD, and CLEAR. The latter consists of CREATE, DROP, COPY, MOVE, and ADD.
I will not go into detail, but SPARQL Update Language delivers a great variety of terms that allows us to manipulate our graphs with SPARQL.
2.1.7 Entailment
An important feature of RDF is the ability to infer knowledge from the existing knowledge, i.e. form or entail new conclusions. This is referred to as entailment. There are multiple forms of entailments in RDF, and it supports one form "out-of-the-box". The document "RDF Semantics"17 gives details about entailment for RDF, RDFS, and D-entailment.
Other regimes are the OWL Direct Semantics18, which covers OWL DL, OWL EL, and OWL QL. There is also RIF, which outlines a core syntax for exchanging rules. The idea is to support multiple rule language, instead of the specific entailment regimes.
As entailment did not become a part of the framework implemented as part of this thesis, I will not go into greater detail at this point. I will return to entailment in section 8.1.3.1, as part of the discussion.
2.2 JS
JS begins its life in 1995, then named Mocha, created by Brendan Eich at Netscape [17,27]. It then got rebranded as LiveScript, and later on JS when Netscape and Sun got together. When the standard was written, it was named ECMAScript, but everyone knows it as JS. It quickly gained traction for its easy inclusion into web pages, but was long ridiculed by developers [15].
Douglas Crockford states in his article "JavaScript: The World's Most Misunderstood Programming Language"19 ten reasons for the confusion centering JS:
- The Name,
- Lisp in C's clothing,
- Typecasting,
- Moving Target,
- Design Errors,
- Lousy Implementations,
- Bad Books,
- Substandard Standard,
- Amateurs, and
- Object-Oriented.
Luckily there has been some changes to the list since its conception in 2001.
Point 1-5 is quite valid yet20, but can be remedied by good and educational resources for learning JS21.
Point 6 is (mostly22) not valid anymore. If the community learned anything from the browser wars, it was to work with the community through the process of standards. Ecma Internationals effort to create a specification based on the de facto standard amongst the browsers has been successful, and groups such as W3Cs HTMLWG and WHATWG drives the production of standards, and great efforts are made to increase efficiency amongst JS-engines. Another testimony to the fact that implementations are increasingly popular are the efforts to use JS as a programming language outside the browser (described in section 2.2.7).
Point 7 depends on your view of good books, and although there is much left to desire, there are some good books out there23. But more importantly, there are several efforts to deliver resources of high quality to educate developers in JS. These resources are increasingly - perhaps fittingly - web-based. There is also an increase of interest on conferences that target developers24.
Point 8 is left to be discussed (I have not read and analyzed the 440 pages that ECMAScript version 3 and 5 consists off), but the implementation of the standards seem to suggest that this point is not so valid anymore.
JS is increasingly becoming part of the professional world, adaptations into conferences being one of the arguments suggesting this trend. You also have examples of major companies either supporting or developing JS-libraries25. This would suggest that point 9 is not the case anymore26.
Point 10 is still valid, as it can be difficult for developers trained in conventional object-oriented languages like Java and C#. Again, as with point 1-5, this is remedied by proper, educational resources, that developers can turn to when puzzled by the intricacies of JS.
JS may be a greatly misunderstood language even today, but it seems to have a lot going for it. The fact that it is the de facto programming language for the web puts it into a position worthy of respect, and should be regarded as a resource which can be used for many great things.
2.2.1 Object-Oriented
JS is fundamentally OO as objects are its fundamental datatype [19,p. 115]. It treats objects different than many other programming languages though, as it does not have classes and class-oriented inheritance. There are fundamentally two ways of building up object systems, namely by prototypical inheritance (explained in section 2.2.1.1) and by aggregation (explained in section 2.2.1.2) [15].
Another design feature is its support of the functional programming style, by treating functions as first-class objects. This feature is explained thoroughly in section 2.2.1.3.
The level of object-orientation in JS is shown in that even literals (i.e. all primitive values except undefined and null) can be treated as objects. They are, however, immutable, and does not share the dynamic properties that "normal" objects in JS do. JS handles this by wrapping the values into their respectively object-type (e.g. String, Number, and Boolean). An example showing this is shown in listing 2.21.
var stringObject = new String('foo');
console.log(stringObject.length); // logs 3
var stringLiteral = 'foo';
console.log(stringLiteral.length); // logs 3
Other objects that are somewhat different from the norm is the Array- and Math-object, the former representing a list of values and the latter sporting a set of static methods.
Objects in JS do not need classes to be instantiated. But it is possible to emulate classes in JS though, as it helps us use class-depended features (e.g. some SDPs), and an example is shown in listing 2.22.
var MyClass = function () {
this.myProperty = 42;
this.myMethod = function (value) {
return value + this.myProperty;
};
};
var myObject = new MyClass();
console.log(myObject.myMethod(1295)); // logs 1337
2.2.1.1 Prototypical Inheritance
At the heart of all object-handling in JS is Object. All objects inherit this object if nothing else is specified, and it is there we find the default properties and methods that are shared by all objects. We can manipulate which object we want our objects to inherit, and as such can create a hierarchy of objects. Listing 2.23 show some examples of inheritance. In it we see how we can initiate objects, and how we can assign them to inherit other objects.
var objectA = {},
objectB = new Object(),
objectC = Object.create(objectB)
objectB.__proto__ = objectA;
Object.propA = 42;
objectB.propA = 1337;
console.log(objectA.propA, objectC.propA); // logs 42, 1337
The simple secret behind prototypical inheritance is that all objects have the property __proto__. When a property or method is called, JS will search for the called element by traversing the objects' properties, and if not found, it will continue with the prototype. We can visualize the structure in listing 2.23 as a tree, and have done so in figure 2.24.
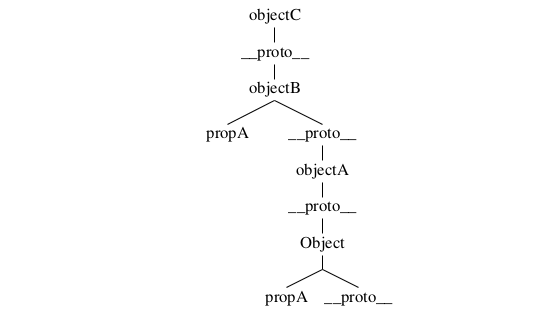
So when we call objectA.propA, JS will check if objectA has the property propA. As it has not it will continue to its prototype, which is Object. Now, as Object has the property propA, JS will return its value, which is 42 in our case. But if we call objectC.prop, it will not have to go longer than objectB to see that there is a property that matches its search.
A last note is that Object also have the property __proto__. This can also be manipulated, but JS will take care so that we do not run into an infinite loop when looking for properties that does not exist (it is also considered a bad practice (i.e. an anti-pattern) to manipulate the prototype of Object).
2.2.1.2 Dynamic Properties
All mutable objects in JS can be manipulated at run-time. This we also see in listing 2.23, as we add the property propA in line 5 and 6. Objects are basically containers for key-value entities, where the key is a string. In this regard, objects in JS can be regarded as maps, or dictionaries.
We can at any time manipulate existing properties by replacing its values or delete the key altogether. We can also manipulate objects that are prototyped, and the objects that inherit will also be affected. The internal works of this is that JS creates a reference in memory for variables that are set as objects. If those variables where to be set to other variables, the reference would be copied, not the values contained within.
A note on mutability and immutability: JS differentiate between primitive values and object. The former are immutable, while the latter is mutable. ECMA5 offers three new functions that alter this behavior, namely the properties seal, freeze, and preventExtensions in Object (with the responding isSealed, isFrozen, and isExtensible to test whether or not these are set) [17,p. 114-115]. Explaining how these functions are outside the scope of this thesis, but suffice to say is that ECMA5 adds some spice to the mutable properties of JS-objects.
2.2.1.3 Functional Features
All functions are treated as first-class objects, and as such can be manipulated as any other object. It can also be passed around as variables, and this opens for some nifty features. By passing a function as a parameter, we can call that function whenever we want, e.g. after we have loaded a set of resource. This asynchronous feature is explained in depth in section 2.2.5.
Functions can be instantiated in many ways, as shown in listing 2.25. A function consists of three elements [19,p. 164]:
- Name: An identifier that names the function (optional in function definition expressions).
- Parameter(s): A pair of parentheses around a comma-separated list of zero or more identifiers.
- Body: A pair of curly braces with zero or more JS-statements inside.
function functionA (x) { return x; };
var functionB = function (x) { return x; },
functionC = function functionD (x) { return x; },
functionE = new Function("x", "return x;");
console.log(functionA(42), // logs 42
functionB(42), // logs 42
functionC(42), // logs 42
functionD(42), // throws ReferenceError: functionD is not defined
functionE(42)); // logs 42
All types in listing 2.25 support these requirements, albeit a little differently. Line 1 shows a named function, while the other two are anonymous. Anonymous functions are called through their reference, i.e. the variables they are set to. Named functions is referable by their names, if not they are set to a variable, in which case it will be referable by the variable (line 9 shows what happens if you call the function by its name when its set to a variable).
Functions of the types listed in line 1-3 can be used as constructors for new objects, while the one in line 4 can be used as a prototype. A simple example of this is shown in listing 2.26. It introduces the use of this, which will be explained in section 2.2.2.
function ObjectA (x) {
this.x = x;
this.methodA = function (y) {
return this.x + y;
};
}
var A = new ObjectA(1300);
console.log(A.methodA(37)); // logs 1337
2.2.2 Scope
The way JS handles the scope may be confusing to developers coming from class-oriented programming languages. JS does not contain syntax such as private of protected for use with variables, but it supports private variables for objects. It does so in the way it handles the context functions are part of (e.g. the scope).
Functions in JS can be nested within other functions, and they have access to any variables that are in scope where they are defined. This means that JS-functions are closures, and it enables important and powerful programming techniques [19].
If a variable is not set as a property in an object, it will be a part of the global object. The global object in JS depends on which environment it is run in, but in most browsers it is represented by the object window. This has some consequences, like the fact that usage of the syntax-element var is optional; it will become a key-value entity in the scope in which it is declared, which is the global object if nothing else is specified. This is exemplified in listing 2.27.
var x = 42; y = 42; window.z = 42; console.log(x, y, z); // logs 42 42 42
2.2.2.1 Closure
Lets review a simple example of closure, given in listing 2.28. In this example we have two functions, one which works as a constructor, and another that merely calls a function it has been given as parameter. When we pass a.getValue to functionA, JS also include the context which that method runs in, in effect creating a closure.
var ObjectA = function (val) {
this.val = val;
this.getValue = function () {
return this.val;
}
},
functionA = function (getFunc) {
return getFunc();
};
var a = new ObjectA(42);
console.log(functionA(a.getValue)); // logs 42
This feature is increasingly used in JS-libraries, and is getting a lot of appraise from the community. But it is also a headache for many aspiring JS-developers, as it may be a bit difficult to wrap your head around (and use correctly). Lets look another example of what may go wrong, given in listing 2.29. In this example we try to access this.val inside functionAA. But as functionAA is not part of the scope of functionA, and thereby not being a part of the closure given to functionB, we fall back to calling on the global object. Since the global object does not have a property named val, it will return undefined.
var functionA = function (val, func) {
this.val = val;
function functionAA () {
return this.val;
}
return func(functionAA);
},
function B = function (func) {
return func();
};
console.log(functionA(42, functionB)); //logs undefined
2.2.3 Static functions
JS supports static functions in that all functions are treated as objects, and by extension can be extended with methods. Listing 2.30 illustrates an example of this.
var funcA = function (val) { this.val = val; },
objA = new funcA(1337);
funcA.funcB = function () { return 42; }
funcA.funcC = function () { return this.val; }
console.log(funcA.funcB()); // logs 42
console.log(objA.funcC()); // throws TypeError
console.log(funcA.funcC.call(objA); // logs 1337
Note that static functions are not accessible as methods in objects constructed with the parenting functions as constructor. But we can manipulate the scope of the functions by overloading this (with call) to be the object we wish to refer to, as shown on line 7.
2.2.4 JSON
JSON is a lightweight, text-based data interchange format. It is originally based on JS, but is language-independent[16]. It was specified by Douglas Crockford in RFC 4627, and enjoys support in most major programming languages.
JSON consists of literals that are either false, null, true, an object (i.e. collections of key-value pairs), an array (i.e. lists), a number, or a string [16]. Listing 2.31 shows some examples of valid JSON-objects, as well as some structures that are not valid JSON.
// valid, can all be parsed by JSON.parse
var goodA = '42',
goodB = '{ "a": 42 }',
goodC = '[ 1337, { "a": 42 }]';
// invalid, will all make JSON.parse throw a SyntaxError
var badA = '', // unexpected end of input
badB = 'function (x) { return x; }', // unexpected token u
badC = '{ "a": new Object() }'; // unexpected token e
JS supports JSON by default (given in ECMAScript Language Definition [17]).
2.2.5 Asynchronous Loading of Resources
Asynchronous loading or resources are common in browsers. Normal HTML documents normally externalize much of its CSS and JS functionality, as dictated by good practices. Those resources are loaded by the browser by default, without too much hassle. But when it comes to making use of the browsers API (i.e. the ones available to JS) to load resources asynchronously, it becomes another game entirely.
2.2.5.1 SOP
As with many issues, handling external resources are difficult in JS because of security issues. And justifiable so, as JS becomes an increasingly powerful programming language, so are the possibilities to abuse it. Users of WWW are increasingly used to insert personal information, and if we cannot trust owners of web pages to control what is being run on their site, then there would be a lot of issues with trust on the web27.
Perhaps the most important security concept within modern browsers is the idea of SOP28. Although there is no single SOP governing how browsers implement it, the idea is that resources that do not share the same origin (i.e. having the same scheme, host, and port in the IRI (concepts explained in section 2.1.4.2)) are isolated from each other.
It is possible to circumvent SOP in JS by inserting a script-tag referring to an external file. This technique is used by JSONP, which allows JSON residing in external files to be loaded during run-time.
2.2.5.2 CSP
Another way of handling security concerning external resources is CSP. CSP is in the works (Working Draft at W3C29), and as an incomplete standard it may be prone to changes. But the basic idea is to let developers whitelist external resources. The policy is first and foremost being designed to be part of the HTTP response header, but there is also work on letting it be a part of HEAD in a HTML document, as a META tag.
2.2.5.3 XHR
XHR has been part of the world of browsers for a while. It was conceived by Microsoft in their work on Microsoft Exchange Server 2000, and was later ported by Mozilla. It was overlooked for quite a while, until AJAX became a trend, as developers understood the power it had to load resources asynchronously (and synchronously, if needed).
XHR2 is a Working Draft as of this writing, but introduces several features requested by the community, allowing cross-domain fetching of resources being one of them. To allow this, it makes use of another standard which is in the making, namely CORS30. This technology is already available in some browsers. But its inherit problem is that it requires domain-owners to add information to their HTTP headers.
Another technology developed to fetch resources across domains are XDR. But as it was not included in the framework, I have let it be a part of the discussion in section 8.1.4.1.
2.2.6 CJS
CommonJS is a volunteer-driven project31 aiming to standardize and implement specifications that expand the functionality of JS. Specifications include handling of modules, unit testing, packaging, I/O, handling of binary data, and much more. We have included details concerning three of these specifications (the promise pattern, section 2.2.6.1 and the module patterns AMD and CommonJS Modules, sections 2.2.8.3 and 2.2.8.4), as they have been included in the framework.
2.2.6.1 Promise Pattern
The promise pattern is titled Promises/A by CommonJS32. It is also referred to as Deferred, and works by having an object represent a promise. The promise consists of a result that will be returned at some time in the future, and in the meantime, the run-time will continue evaluating the rest of the sourcecode. This can be set up so that when the result is ready, a function is called with the result sent as parameter. This allows for some proper handling of asynchronous functionality.
Listing 2.32 shows some examples of the API. A central point of these examples are that the functions passed as parameters to the then-function are called as soon as the promise are resolved, i.e. detached from the order in which they were called in the code.
// When is available as a global variable
var promiseA = When.defer(),
promiseB = When.defer();
setTimeout(function () { promiseA.resolve(42); }, 2000));
setTimeout(function () { promiseB.resolve(1337); }, 1000));
// Preparing single promises
promiseA.then(function (result) {
console.log(result); // logs 42 after 2000 milliseconds
});
promiseB.then(function (result) {
console.log(result); // logs 1337 after 1000 milliseconds
});
// Preparing multiples promises
When.all([ promiseA, promiseB ], function (results) {
console.log(results); // logs [ 42, 1337 ] after 2000 milliseconds
});
2.2.7 Server-side implementations
As JS has become an increasingly popular programming language, so has its use outside of the browser. One of these branches is the use of JS for server-side web-applications. As part of this thesis I have only used one such implementation as a run-time environment for my TDD. A more in-length discussion of the matter can be found in section 8.1.5.
2.2.8 Module Patterns
JS is a flexible language, and one area in which this is very clear is when it comes to module handling. This is not a surprise, as handling variables and ensuring they are not compromised by code elsewhere in the application is harder than you might think. As such, "modules are an integral piece of any robust application's architecture and typically help in keeping the units of code for a project both cleanly separated and organized" [29].
This section will describe some of the patterns of module handling I have found during my research.
2.2.8.1 Contained Module
The Contained Module pattern is designed to encapsulate private variables and return an explicit object with public methods that can work with the private variables. It was made popular by Douglas Crockford, and is used extensively in smaller libraries. Listing 2.33 shows an example using this pattern.
var myModule = (function () {
var myPrivateVariable = 42;
function myFunction () {
return myPrivateVariable;
}
return {
myPublicFunction: myFunction
};
})();
console.log(myModule.myPublicFunction); // logs 42
The problem with this pattern is that it does not really address how to combine several modules. For that we turn to the other patterns.
2.2.8.2 Namespaces
The simplest way structure several modules is to follow the Namespaces pattern. An example of it can be seen in listing 2.34.
var OurNamespace = {};
// in another file, called after the above code has been evaluated
(function (ns) {
ns.anotherLevel = {};
})(OurNamespace);
// another file yet again, called after the above code
(function (ns) {
ns.anotherLevel.ourFunctionalModule = function () { /* ... */ };
})(OurNamespace);
It requires the developer to include the modules in correct order, which can be troublesome. The one single argument to use this is that it is supported out-of-the box, as it does not depend on any extra functionality than the one inherent in browsers.
2.2.8.3 AMD
The AMD pattern is titled Modules/Async/A by CommonJS33. Its overall goal is to provide a solution for modular JS that developers can use today[29]. Essentially it makes use of the functions define and require. The former defines a module, while the latter enables us to load dependencies that the module requires. Listing 2.35 shows an example.
define([
"dependentModuleA",
"dependentModuleB"
], function (depModA, depModB) {
function privateFunction () {
/* This function is not publicly available by other modules */
}
return { /* This object becomes available to other modules */
myPublicFunction: function () { /* ... */ }
};
});
AMD allows us to split our functionality into modules and easily load components as they are needed, in run-time. This in turn leads do a more decoupled code base, making it easier to make modules reusable. But it may also increase the loading time required, as each module requested fires a HTTP request. Which consequences this has for the framework is further discussed in section 8.1.2.
2.2.8.4 CommonJS Module
Another pattern to emerge from the CommonJS community the CommonJS Module pattern. It makes use of the functions require and exports. An example is given in listing 2.36.
var moduleDependency = require("moduleWeAreDependentOn");
function privateFunction () {
/* This function is not publicly available by other modules */
}
exports.myModule = { // this object is available to other modules
myPublicFunction: function () { /* ... */ }
};
CommonJS also allow modules to be loaded asynchronously34, and in many regards resembles AMD a lot. AMD and CommonJS Module differ in which environment they cater to. AMD is mostly being used by client-side projects, while CommonJS Modules is used by server-side projects. That said, both types can be used on either sides, and it becomes merely a question of taste.
2.2.8.5 Harmony
Last, we have the modular pattern that is to be part of the sixth edition of EcmaScript, a.k.a. ES.next, a.k.a. Harmony. This pattern makes use of new syntax, and an example can be seen in listing 2.37.
module moduleA {
export var functionA = function () { /* ... */ }
export var objectA = { /* ... */ }
export var propertyA = 42;
}
module moduleB {
import functionA, objectA, propertyA from moduleA;
// equivalent to the above: import * from moduleA;
}
This syntax is not available in standard browsers yet, as it is still subject to change, however it is available for experimentation through tools such as traceur-compiler35 and esprima36.
2.3 SDP
Patterns were originally conceptualized as an architectural concept by Christopher Alexander, who wrote:
Each pattern describes a problem which occurs over and over again in our environment, and then describes the core of the solution to that problem, in such a way that you can use this solution a million times over, without ever doing it the same way twice [1,p. x].
Alexander's work inspired amongst others Kent Beck and Ward Cunningham, who in 1987 presented the report "Using Pattern Languages for Object-Oriented Programs"37 on OOPSLA-87. They outlined the adaptation from Pattern Language to object-oriented programming, and summarized a system of five patterns that they had successfully used for designing window-based user interfaces.
SDPs did not become popular before the publication of Design Patterns by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (often known as GoF) in 1994. They generalized patterns to have four essential elements (all quoted in shortened from Design Patterns [22,p. 3]):
- Pattern name: A handle which we can use to describe a design problem, its solutions, and consequences in a word or two. A pattern name is useful as a higher level of abstraction, increases our pattern vocabulary, and eases communication in social contexts.
- Problem: Each pattern is designed to handle a specific problem, and this part tells us when it is appropriate to use a specific SDP.
- Solution: This part explains in detail how to solve the given problem by explaining the elements that make up the design, their relationships, responsibilities, and collaborations.
- Consequences: All implementations have consequences, and this part tells us what results and trade-offs we may expect from applying the pattern. Consequences may be how the pattern affects a system's flexibility, extensibility, or portability.
In their book they also design a classification scheme that aims to enable developers to refer to families of SDPs. One categorization is by purpose, which can be either creational, structural, or behavioral. The second categorization is by scope, which can be classes or objects. SDPs that are related to this thesis have been classified in table 2.3.
| Purpose | ||||
|---|---|---|---|---|
| Creational | Structural | Behavioral | ||
| Scope | Class | Adapter | Interpreter | |
| Object | Builder | Adapter | Observer | |
| Prototype | Bridge | Strategy | ||
| Composite | ||||
| Decorator | ||||
| Facade | ||||
| Proxy | ||||
At this point I need to make two points clear. The first is that as JS is a class-less programming language, the categorization class might be a bit off. But remember that we can emulate classes in JS, and this allows us to make use of the class-categorized patterns. The other point is that JS does not support interfaces. Interfaces can be emulated (at the cost of complexity), but is not anything more than a construct that checks whether or not a list of properties is set at run-time. It is on the base of this that I have excluded the use of interfaces in this thesis, falling back to merely describing the abstractions of participants, and how they are represented in the code samples38.
GoF continues to describe a consistent format for describing SDP, which including Pattern Name and and Classification, Intent, Also Known As, Motivation, Applicability, Structure, Participants, Collaborations, Consequences, Implementation, Sample Code, Known Uses, and Related Patterns. Using all of these labels takes a lot of pages, and in this thesis I have limited myself to a description of the pattern along with a figure and an example in JS.
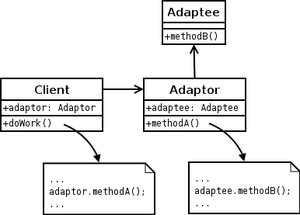
2.3.1 Adapter
The Adapter pattern "convert the interface of a class into another interface clients expect" [22]. This pattern is useful when one wishes to make use of third party libraries without modifying them. In its classic form, the Adapter pattern are both a class and an object pattern, where the former makes of subclassing, while the latter forms a reference to the components it adapts, thereby routing requests.
In listing 2.39 I have shown examples of both. Line 4 shows subclassing through Object.create, which enables derivatives of AdapterClass to make use of the methods in the Original object. Line 5 shows the constructor function that returns an object that refers to the Original object, and thereby allows routing of calls.
I have not made use of the Adapter pattern in Graphite, a point I return to in section 8.2.1.1 in the discussion.
var Original = {
originalMethod: function (options) { /* ... */ }
},
AdapterClass = Object.create(Original).
AdapterObject = function () {
return Object.create({
adapterMethod: function (paramA, paramB) {
return this.target.originalMethod({ a: paramA, b: paramB });
}
}, {
target: { value: Object.create(Original); }
});
};
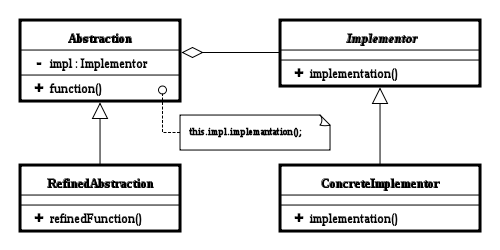
2.3.2 Bridge
The Bridge pattern "decouple an abstraction from its implementation so that the two can vary independently" [22]. The pattern is actually often used in JS in terms of event handling, using code such as the one in listing 2.41. In that case, the abstraction is that a function is to be called when a specific button is called, the refined abstraction is the actual functions. The implementor on the other hand is a function that takes the id to the button to be handled, and the abstraction that is to be coupled. The concrete implementor is the function handleClick, which configures the setup needed.
We could have implemented another abstraction, namely making sure that whatever was passed as handleClick's first parameter was an object that supported the onclick property. This way, I could have removed the limitation of sending just strings of ids, e.g. passing the object returned from document.getElementByClass("buttons").
var cancelFunction = function () {
console.log("Cancel was clicked");
},
submitFunction = function () {
console.log("Submit was clicked");
},
handleClick = function (buttonId, func) {
document.getElementById(buttonId).onclick = function () {
func();
return false;
};
};
handleClick("CancelButton", cancelFunction); // When clicked, will log "Cancel was clicked"
handleClick("SubmitButton", submitFunction); // When clicked, will log "Submit was clicked"
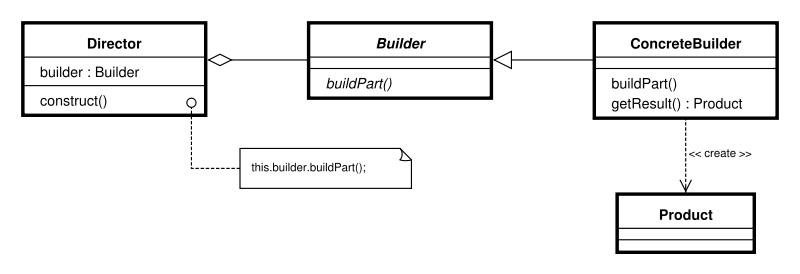
2.3.3 Builder
The Builder pattern "separate the construction of a complex object from its representation so that the same construction process can create different representations" [22]. A good example of this is the way jQuery allows us to construct DOM elements (listing 2.42).
var paragraph = $("<p>"),
titleWithText = $("<h1>Our title</h1>"),
inputWithAttr = $('<input type="password" />');
These lines should be very easy to read for developers familiar with HTML, and handles a lot of logic that is run behind the scene (e.g. the use document.createElement, adding attributes, and text).
Now, lets look at listing 2.44 for my own version of a DOM-builder (a very limited version, i.e. it only support one level of element). I have removed parts of the code, as they unnecessary to understand how the pattern works. The participants are DOMCreator (the Director), DOMBuilder (ConcreteBuilder), and DOMElement (the Product). The code works in following steps:
- We pass to DOMCreator the string we want parsed.
- DOMCreator creates an instance of DOMBuilder, and passes along the tag.
- DOMBuilder creates an instance of DOMElement, and sets the tag.
- DOMCreator parses attributes, if any, and passes them to DOMBuilder.
- DOMBuilder adds attributes to the DOMElement.
- DOMCreator parses text, if any, and passes it to DOMBuilder.
- DOMBuilder adds text.
After these steps, the client can fetch the element by calling getElement on DOMCreator.
var DOMElement = {
attributes = {},
tag = null,
text = ""
},
DOMBuilder = function (tag) {
this.element = Object.create(DOMElement);
this.element.tag = tag;
this.addAttribute = function (key, value) {
this.element.attributes[key] = value;
}:
this.addText = function (text) { this.element.text = text; };
},
tokens = {}, // a map of tokens to parse
fetch = function (str, token) {}, // returns specified type of token
remove = function (str, token) {}, // removes token, returns modified string
test = function (str, token) {}, // tests for specific token, return boolean
DOMCreator = function (str) {
var key, tag, text, value;
// fetches the tag
this.builder = new DOMBuilder(tag);
while (test(str, tokens.whitespace)) {
// fetches key-value pair of attributes, if any
this.builder.addAttribute(key, value);
}
if (!test(str, tokens.slash)) {
// fetches text, if any
this.builder.addText(text);
}
// We have what we need
};
DOMCreator.prototype.getElement = function () {
return this.builder.element;
}
var element = new DOMCreator("<p>42</p>");
console.log(element.getElement()); // logs { attributes: {}, tag: "p", text: "42" }
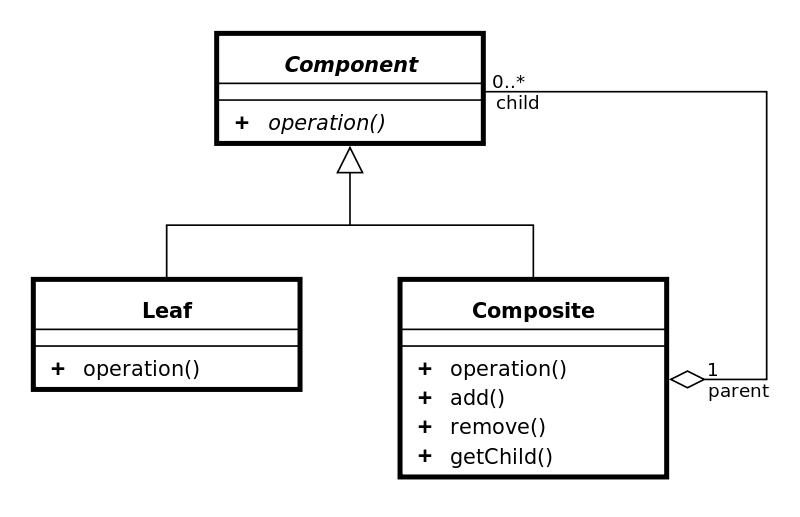
2.3.4 Composite
The Composite pattern "compose objects into tree structures to represent part-whole hierarchies."[22]. This is a method of abstracting the types of a complex structure, and streamlining certain procedures. In listing 2.46 I have continued with the DOM, and created a structure that represents DOM elements that can be used to generate HTML.
In this example we have two Composites (DOMComposite, DOMElement) and one Leaf (DOMText). The client gets the HTML by calling the method getHtml on any of the elements desired, and they will take care of producing the result from all nested, if any, elements.
var DOMComposite = function (children) {
this.children = children;
},
DOMElement = function (tag, content) {
this.tag = tag;
this.content = content;
},
DOMText = function (text) {
this.text = text;
};
DOMComposite.prototype = {
addChild: function (element) {
this.children.push(element);
},
getHtml: function () {
var child, html = "";
for (child in this.children) {
html += child.getHTML();
}
return html;
}
}
DOMElement.prototype.getHtml = function () {
var text = "<" + this.tag;
if (this.content) {
return text + ">" + this.content.getHtml() + "</" + this.tag + ">";
}
return text + " />";
};
DOMText.prototype.getHtml = function () {
return this.text;
}
var text1 = new DOMText("42"),
text2 = new DOMText("1337"),
composite1 = new DOMComposite([ text1 ]),
element1 = new DOMElement("span", text2),
composite2 = new DOMComposite([ composite1, element1 ]);
console.log(composite2.getHtml()); // logs "42<span>1337</span>"
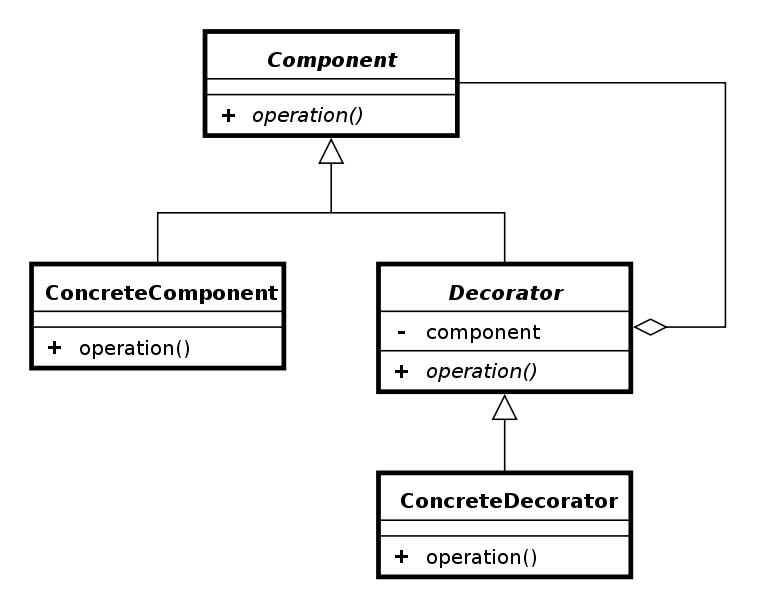
2.3.5 Decorator
The Decorator pattern "attach additional responsibilities to an object dynamically" [22]. As JS is dynamic in its nature, this is not a very difficult pattern to implement. In listing 2.48, I have simplified the example used by Addy Osmani in his book Learning JavaScript Design Patterns39.
To use the participants in figure 2.47, we have PC as ConcreteComponent, and addMemory, addScreen, and addKeyboard as the ConcreteDecorators.
var PC = { cost: function () { return 1000; } },
addMemory = function (PC) {
return PC.cost: function () { PC.cost() + 300; };
},
addScreen = function (PC) {
return PC.cost: function () { PC.cost() + 30; };
},
addKeyboard = function (PC) {
return PC.cost: function () { PC.cost() + 7; };
},
myPC = Object.create(PC);
addMemory(myPC);
addScreen(myPC);
addKeyboard(myPC);
console.log(myPC.cost()); // logs 1337
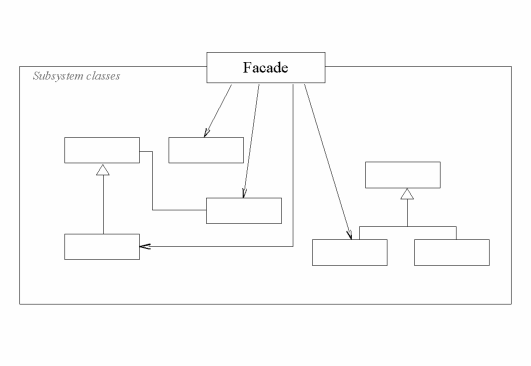
2.3.6 Facade
The Facade pattern "provide a unified interface to a set of interfaces in a subsystem" [22]. Again, jQuery shows us an example of design pattern, as the constructor of the jQuery-object applies the Facade pattern. It is usually used to simplify the API the user have to concern himself/herself with, by delivering a subset of methods from underlying modules.
In listing 2.50, I have designed an object that takes the libraries jQuery and when.js, and delivers a new interface that taps into some of their functionality. The facade in the example have one method, namely load, and promises to load the callback functions in the order they are used (i.e. http://example.org/1337 will not be loaded before http://example.org/42 has completed).
// assumes $ and When are global variables
var facade = (function (jQuery, When) {
var promise = null;
function load (uri, callback) {
promise = When.defer();
jQuery.get(uri, {}, function () {
promise.resolve(arguments);
callback.apply(this, arguments);
});
}
return {
load: function (uri, callback) {
if (promise) {
promise.then(function () {
load(uri, callback);
});
} else {
load(uri, callback);
}
}
};
}($, When));
facade.load("http://example.org/42", function () {
console.log(42);
});
facade.load("http://example.org/1337", function () {
console.log(1337);
});
// Console will always log 42 first, 1337 second
2.3.7 Interpreter
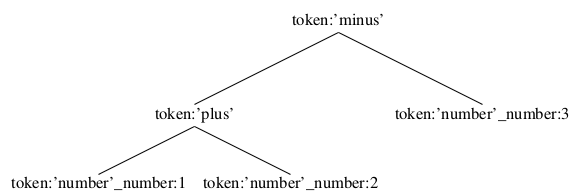
The Interpreter pattern takes a given language and "define a representation for its grammar along with an interpreter that uses the representation to interpret sentences in the language" [22].
In my simple example I want to be able to parse simple equations, using the following rules:
- Legal tokens are plus, minus and numbers, and these tokens are represented as expressions.
- It reads the equation from left to right.
- No whitespace allowed.
- The plus and minus expression take the its left expression as parameter, and expects a number to come after it (e.g. "1+44-3" and "-2+3" are both allowed, but "2++3" is not).
The result is an object with a tree-structure consisting of my grammar. E.g. the equation "1+2-3" would look like figure 2.51.
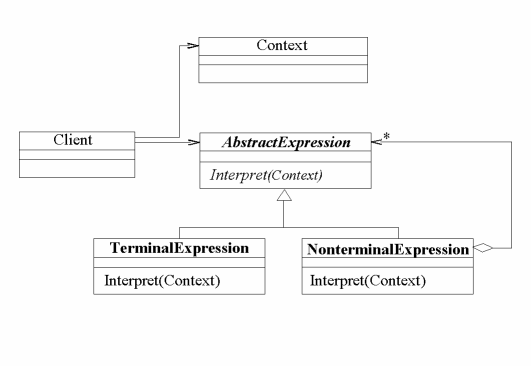
function parseEquation = function (equation) {
var grammar = {
minus: function (left, right) { return { token: 'minus', left: left, right: right }; },
number : function (number) { return { token: 'number', number: number }; }
minus: function (left, right) { return { token: 'plus', left: left, right: right }; },
},
tokens = {
minus = {
expression: /^-/,
evaluate: function (base) {
var right = tokens.number(base);
base.eq = base.eq.substring(1);
return grammar.minus(base.left, right);
}
},
number = {
expression: /[0-9]+/,
evaluate: function (base) {
var value = this.expression.exec(base.eq)[0];
base.eq = base.eq.substring(value.length);
return grammar.number(value);
}
},
plus = {
expression: /^+/,
evaluate: function (base) {
var right = tokens.number(base);
base.eq = base.eq.substring(1);
return grammar.plus(base.left, right);
}
}
};
this.left = grammar.number(0);
this.eq = equation;
while (this.eq !== "") {
if (tokens.minus.expression.test(this.eq)) this.left = tokens.minus.evaluate(this);
else if (tokens.number.expression(this.eq)) this.left = tokens.number.evaluate(this);
else if (tokens.plus.expression.test(this.eq)) this.left = tokens.plus.evalue(this);
else throw new Error("No valid expression");
}
return this.left;
}
2.3.8 Observer
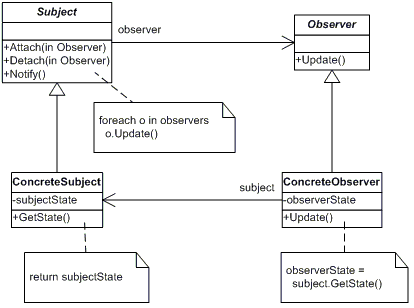
The Observer pattern "define a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically" [22]. This is useful when objects are dependent to know when a dependency changes state, as they will be notified when change happen.
I have included a simple example in listing 2.55. This can be evolved into context-aware notifies, so that observers only are notified when certain things happen. Note that I have made use of closure (section 2.2.2.1) in this example, as the object called upon in line 22 actually is the object first passed in the obsObject construct-function (line 19).
var obsSubject = function () {
this.observers = [];
this.value;
this.addObserver = function (observer) {
this.observers.push(observer);
};
this.notify = function () {
var observer;
for (observer in this.observers) {
observer.update();
}
};
this.getValue = function () { return this.value; };
this.setValue = function (val) {
this.value = val;
this.notify();
};
},
obsObject = function (subject) {
subject.addObserver(this);
this.update = function () {
console.log("New value: " + subject.getValue());
}
},
mySubject = new obsSubject(),
myObj1 = new obsObject(mySubject),
myObj2 = new obsObject(mySubject);
mySubject.setValue(42); // logs "New value: 42" two times
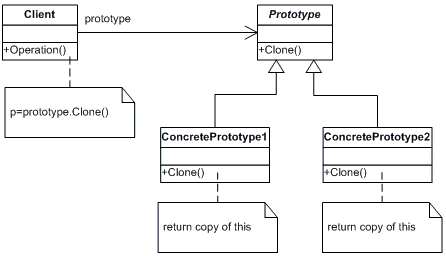
2.3.9 Prototype
The Prototype pattern "specify the kinds of objects to create using a prototypical instane, and create new objects by copying this prototype" [22]. The variation from how JS handles prototypical inheritance (section 2.2.1.1) is slight, as JS handles prototyping by copying the reference to the prototype object, while the pattern copies the whole thing.
The example given in listing 2.58 shows this in action. Line 18 shows what happens if you compare the prototype object of two objects that have been created using Object.create in JS, compared to what happens if you compare the cloned objects. The references are different.
The pattern is not specified in the description of the modules in Graphite, but is included here to show how it differs from prototypical inheritance. It has been used throughout the framework, although as the function named extend (that resides in the Utils module). Most often it is used in pair with the parameter option given to functions that offer slight variations from its default behavior. An example is given in listing 2.56.
// assumes a global function extend that functions like the Prototype pattern
var myConfigurableFunction = function (options) {
var defaultConfig = extend({
configurationA: true,
configurationB: 42
}, options);
/* Rest of the functions body */
};
myConfigurableFunction({ configurationB: 1337 }); // overwriting the default value 42
var Prototype = {
methodA: function () { /* ... */ },
objectA: { /* ... */ },
propA: { /* ... */ }
};
function clone (obj) {
var o = {}, key;
for (key in obj) {
if (typeof obj === "Object") o.__proto__[key] = clone(obj[key]);
else o.__proto__[key] = obj[key];
}
return o;
}
var a = Object.create(Prototype),
b = Object.create(Prototype),
c = clone(Prototype),
d = clone(Prototype);
console.log(a.__proto__ === b.__proto__); // logs true
console.log(c.__proto__ === d.__proto__); // logs false
2.3.10 Proxy
The Proxy pattern "provide a surrogate or placeholder for another object to control access to it" [22]. There are several kinds of proxies, like the virtual proxy (works like a lazy instantiator, i.e. only creating the proxied object when you need it), remote proxies (proxies an object on a remote destination), and controlling proxies (to handle access), and they may be combined.
In listing 2.60 I have constructed a remote proxy. The object it proxies has one single purpose, which is to fetch the resource located at a given IRI. This may be one way of circumventing SOP (section 2.2.5.1).
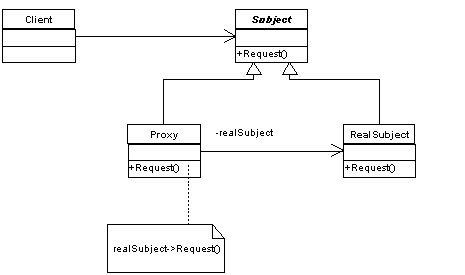
// assumes function ajax, that acts like $.ajax
var proxy = function (iri, callback) {
ajax(/localproxy/, {
data: {
iri: iri
},
method: get,
success: callback
});
};
proxy("http://another.domain.com/42", function (data) {
console.log(data); // logs whatever was fetched from http://another.domain.com/42
});
2.3.11 Strategy
The Strategy pattern "define a family of algorithms, encapsulate each one, and make them interchangeable" [22]. It relies on a shared interface of properties among objects, and an example is shown in listing 2.6240.
This pattern streamlines the functionality by eliminating conditional statements.
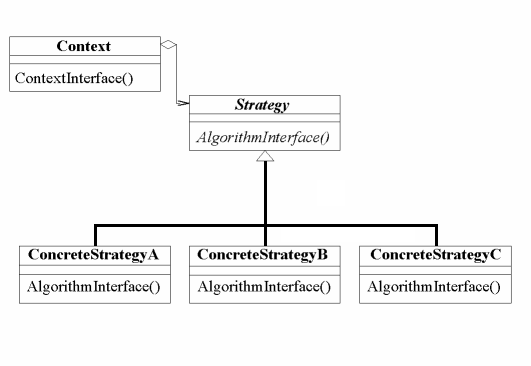
var buttons = [{
id: "Button42",
onclick: function () {
console.log(42);
return false;
}
}, {
id: "Button1337",
onclick: function () {
console.log(1337);
return false;
}
}],
button;
for (button in buttons) {
document.getElementById(button.id).onclick(button.onclick);
}
2.4 TDD
TDD is a development process of software that details how to build your code base. It relies on an iterative cycle of steps that are summarized in figure 2.63. The process start with writing a test that asserts the functionality we wish to implement. It should raise a red flag when first tested (meaning that the functionality is not implemented yet), which in turn leads us to implement the requested feature. When we manage to get a green flag (meaning that the functionality now exists), we can continue to either write a new test for a new functionality, or we can refactor the existing code by making sure it does not raise any red flags (break any tests).
Chapter 3
Problem Description and Requirements
The notion of RDF as a standard for exchanging structured data on WWW is becoming increasingly popular. The technologies of SW are actively developed, and new features, as well as stabilizing old ones, are in the works.
JS has also gotten a lot of attention as an increasingly powerful programming language for WWW. First and foremost as a client-side scripting language, but now also as server-side implementations. Large companies like Google, Microsoft, Mozilla, Apple, and Opera are all putting a lot of effort into increasing the effectiveness of their JS-engines, through implementations and cooperating in evolving the standards.
In this environment, you would think that many developers would try to access SW with a library written in and for JS. While there are projects trying to create frameworks for accessing, query, and manipulating SW, none of them are the defining prototype of a JS-framework for SW as of yet.
3.1 Problem
This thesis seeks to define what is needed in order to have a powerful framework in JS that can access SW. This goal is divided into four subgoals:
- The first subgoal is to identify the features that a framework accessing SW needs to support. Which technologies needs to be involved, what obstacles do they introduce, and what are the consequences of implementing them?
- Next, I need to identify the participants and how they should collaborate. I will try using the knowledge of SDP to describe the components in known and widely utilized language. While doing this, I need to explore how JS conform to the patterns of the various SDPs.
- My third subgoal is to implement a functional framework in JS. In doing this, I need to identify what features JS offers that are relevant for my framework.
- My final goal is to develop APIs that exposes the functionality of the framework in a way that is easy for developers to get into.
3.2 What are the components required for the framework?
I have identified a lot of the technologies regarding SW in section 2.1. RDF and its serializations need to be a part of the framework. As documents containing RDFS, OWL, and other vocabularies, are subsets of RDF, a representation of RDF should be enough in terms of representing the model.
After I have implemented a model of RDF, I need to implement some way of letting developers browse, or query, the data. SPARQL is a powerful language that handles this purpose, but does it raise the bar for using the framework unnecessarily high? Will developers new to SW want to tackle SPARQL in addition to all the other technologies they need to learn?
Another important feature of the framework will be the APIs. How should I expose the functionality to developers? Should it be available as one monolithic object, or is there a need to divert it into several smaller objects? This problem is further investigated in section 3.5.
3.3 Which SDPs are applicable for the components?
I have decided to use SDP to help me decide how I should model the components. This will hopefully help me in identifying participants, collaborations between the participants, and the consequences of implementing them.
Section 2.3 explained in detail the SDPs I think are appropriate for the framework. But these patterns were originally developed for class-oriented programming languages (e.g. C++, which was used to write the sample code used in Design Patterns). Is it appropriate to apply these patterns to a class-less programming language like JS? And if not fully compatible, are there ways to "tweak" the premises, so that we may use the amassed knowledge of patterns to our advantage?
3.4 Which features in JS are of use for the framework?
What are the challenges the framework will have to deal with when implementing the required components? And how does JS align with these problems? I have described JS in section 2.2 and featured some of the functionality that are relevant for my framework.
Serializations will most likely need to be loaded asynchronously. This is handled by the asynchronous loading capacities described in section 2.2.5. I also need certain functions to be called in correct order in response to the asynchronous functionality. By making use of the functional features of JS (section 2.2.1.3), in combination with the promise pattern (section 2.2.6.1), I believe this to be achievable.
3.5 How should the API be designed?
Although SDPs gives a lot of hints as how to design the components, most of the signature of the objects are still up to grab. What are the possibilities we have within the restrains of SW and JS. What is the most effective API to expose to JS-developers that wish to harness the structural data in SW?
How big should it be? How much of the API should be public, i.e. how granular should the functions be? Should it be modularized, or just offer one monolithic API?
These are questions I hope to offer an answer to in my implementation of an actual, working framework.
Part 2
Implementation
Chapter 4
Tools
This chapter will describe the software and services I have used in this thesis.
4.1 Buster
Buster is a "JavaScript test framework for node and browsers"[36]. It has been in beta for a couple of years, and shows promising results. The lead developers hope to have it ready by the end of this summer.
Some important features of Buster are:
- Supports tests for Node and browsers: You can use the same test cases for both environments, but also create dependencies by the use of feature detection.
- Test utilities: Assertions, refutations, stubs and spies, expectations, events, properties, and supporting utilities and objects; There are a lot of possible ways to test your code.
- Flexibility: There is a lot of public APIs, which can be used to write specific code as needed.
- Extensibility: There are already several extensions available, such as buster-amd and buster-lint.
- Asynchronous testing: Buster can test resources that only are available in asynchronous functions.
- Structuring: Nested test cases, setup, and teardown helps you structure and reuse code easier.
- Deferred tests: Easy seclusion of tests that clutters your reports, e.g. while refactoring.
- Measuring time: It reports in milliseconds the duration of each test run.
Graphite has used Buster extensible throughout its development, and now sports 29 test cases, with 430 tests, with a total of 1 413 assertions. It is all being run in about 8 seconds.
Buster is available at GH41, and is being led by August Lilleaas and Christian Johansen.
4.1.1 Browsers
Throughout the testing with Buster I have used Chrome for Linux. The last run with Firefox shows that 4 tests fail in Firefox. I have not tried testing on browsers on other platforms recently, because:
- Buster is not available for Windows yet (and I have not been able to access a Mac for setting up my tests), and
- Many of the tests require resources to be loaded with XHR, which makes using Busters test-server to run tests on other computers somewhat hazy.
4.1.2 Node
Buster is dependent on Node, and as such has used it throughout the development. Node is "a platform built on Chrome's JavaScript runtime for easily building fast, scalable network applications"[38].
Node supports a great list of features, amongst them:
- Modules: A simple module loading system.
- Networking utilities: Setting up servers (e.g. with HTTP, HTTPS and net), creating sockets (e.g. with net and UDP), lookup DNS, handling URLs and queries.
- File System utilities: File I/O are simplified with modules such as File System, path, and os.
- Binary Data utilities: APIs for handling streams and buffers, easing the handling of transmitting binary data on WWW.
- Much, much more.
Node is available at http://nodejs.org and latest versions at GH42. Originally created by Ryan Dahl in 2009, it is now sponsored by Joyent, his employer, and enjoys contributions of many, many developers.
4.2 RequireJS
RequireJS is "a JavaScript file and module loader" [39]. It allows modularization of JS by deploying functionality throughout several files, or modules. It ties it all together by supporting technologies such as AMD (explained in section 2.2.8.3).
Below are some of the features of RequireJS:
- Loading of modules through AMD for browsers, Rhino (an implementation of JS written in Java43), and Node.
- Code optimizing.
- Threading by utilizing Web Workers.
Graphite has used RequireJS to include the vast list of modules as they are needed.
4.3 Git
Git is a free and open source DVCS, originally created by Linus Torvalds as a response to existing VCSs and SCMs. It is fast, reliant, and relatively easy to use. It offers a variety of features, such as (quoted from the documentation [37]):
- Setup, configuring, getting and creating projects.
- Branching and merging, sharing and updating.
- Inspect and compare code.
- Much, much more44.
Graphite has used Git to share its code base, making it available for all to use and contribute to.
4.3.1 GH
GH is a service that lets you share and collaborate with developers45, be they friends or strangers. It is a social network that uses Git as its technological foundation, making it easier to connect with other developers. It supports features such as:
- User and organization-accounts.
- Free git-repositories (as long as they are open source).
- Secure transmissions.
- Utilities for presentation of text and code, such as pages, wikis, gists (usually to present snippets of code), issues management, and graphs (visual presentations of data, such as contributors, commit activity, etc).
Graphite has used GH as a central repository for its code base, which is available at https://github.com/megoth/graphitejs.
4.4 WS
WS is a JS IDE that is available for Windows, Mac OS, and Linux. It offers a wide array of tools for developing with JS, such as:
- Refactoring.
- Structuring code consistently.
- Integration with GH, Node, and JsTestDriver (test framework for JS, developed by Google).
- Smart duplicated code detector.
- Much, much more46.
The development of Graphite has been done primarily in WS.
WS is being developed by JetBrains, is primarily licensed, but offers free licenses for educational and open source purposes. It is available at http://www.jetbrains.com/webstorm/.
Chapter 5
Used Libraries
DRY is a well-known TLA amongst developers. Another similiar but not so known TLA is DRO. In designing Graphite I have tried sticking to these principles (amongst others), which have resulted in making use of some third party libraries.
AMD introduced some restrictions to how I could modularize the components I wanted to reuse, and as such there has been some rewriting across the board. The level of rewriting have varied, but unless otherwise noted in the descriptions of the modules in chapter 6, it limits itself to the necessary steps to make it compatible with the AMD pattern.
5.1 Branches
In order to make it clearer where the code in Graphite origins, I have divided all modules into branches. The modules within the Graphite branch represent original code or components which are modified in a degree that makes them differ significantly from their original counterpart. The four other branches are rdfQuery, rdfstore-js, Underscore.JS and when.js, and table 5.1 shows the distribution. The code in the modules listed under these four branches are similar to their original counterpart, and is therefore not considered to be part of my original contributions to Graphite. The branches are explained in the remaining sections of this chapter.
| Graphite | rdfQuery | rdfstore-js |
|---|---|---|
| API | CURIE | Abstract Query Tree |
| Graph | Datatype | B-Tree |
| Graphite | RDF/XML | Backend |
| JSON-LD | Turtle | Callbacks |
| Loader | URI | Engine |
| Proxy | Lexicon | |
| Query | Underscore.JS | Query Filters |
| Query Parser | Utils | Query Plan |
| RDF | RDF JS Interface | |
| RDF JSON | when.js | SPARQL Full |
| RDF Loader | Promise | Tree Utils |
| RDF Parser | ||
| SPARQL | ||
| XHR |
5.2 rdfQuery
rdfQuery describes itself as "an easy-to-use JavaScript library for RDF-related processing"[42]. It depends on jQuery, and is distributed in three versions:
- Core rdfQuery: Creates and queries triplestores.
- rdfQuery with RDFa: Parses RDFa.
- rdfQuery with rules: Enables reasoning with rules.
rdfQuery has several contributors to its official project-page47, which is led by Jeni Tennison, Rene Kapusta, and Haymo Meran. After a long time of development seemingly going dead, it now has a repository on GH48, which seems to be led by Sebastian Germesin. The repository is a mirror of the original project, and all contribution to the GH-project are contributed back to the official project-page.
5.3 rdfstore-js
rdfstore-js describes itself as "a pure JavaScript implementation of a RDF graph store with support for the SPARQL query and data manipulation language"[23]. It supports a range of features:
- Works in browsers as well as server-side.
- Full support of SPARQL 1.0 and SPARQL Update Language, and partially SPARQL 1.1 (including partial support for property paths).
- Parsers for JSON-LD, Turtle, and N3.
- Implemented W3C RDF Interfaces API49.
- Have an experimental implementation of RDF graph evens API.
- Custom filter functions.
- Threaded API if WebWorkers are supported.
- Persistent storage with HTML5 LocalStorage (for browsers) or MongoDB (for Node).
- Implementation of the SPARQL Protocol for RDF50 on the server-side.
rdfstore-js is available as a repository at GH51, and has a nice pace of development. Its author, Antonio Garrote, also lists Christian Langanke as contributor.
5.4 Underscore.JS
Underscore.JS is a "utility-belt library for JavaScript [which] provides about 80 functions" [41]. Although JS brings a lot to the table in terms of flexibility and a growing set of APIs (both client-side and server-side), it still lacks somewhat when it comes to utility functions. Underscore.JS is a response to this, and provides handy functions that either functions as shivs (e.g. for older browsers that do not support forEach yet) or new altogether. Underscore.JS is available on http://underscorejs.org/.
Further explanation of the usage of Underscore.JS is in section 6.16.
5.5 when.js
when.js is a "lightweight CommonJS Promises/A and when() implementation" [14]. It allows usage of the Promises pattern (section 2.2.6.1), and also provides several other useful Promise-related concepts. It is being developed by Brian Cavalier, and is available at GH52.
The module named Promise is an integration of when.js into Graphite, and further explanation of the module is in section 6.8.
Chapter 6
The Graphite Framework
This chapter will list all the modules that have been implemented. They are listed alphabetically, but some are nested within others. The first level of modules are named main modules, while those nested within them are submodules. I have nested a module if its dependent only by a certain group of modules, with the main module being dependent by other modules.
The names should reflect their purpose, and as such should give an intuitive hint of what they can do. Apart from their names, all modules have a list of features that are presented in the beginning of their section. The list contains the following attributes:
- Branch: The branch in which they reside (explained in section 5.1).
- Location: The address to which they are located in the src-folder.
- Dependencies: Lists which modules, if any, that the module are dependent on.
- Design Pattern: The design pattern(s) that have been used as a starting point for this module, if any (not applicable for third party derived modules).
- Test result: Most modules have tests written as part of their development, and their results are listed here. A complete overview of the test results can be found in appendix B.
After the initial block detailing the attributes, a description explains the module in detail. Considerations taken along the development will be noted, and variations/possibilities explained.
Dependencies between the main modules have been visualized in figure 6.1. The dependencies within each subdomain of modules are listed in their designated main module.
The source can be forked at https://github.com/megoth/graphitejs.
6.1 API
| Branch | Graphite |
| Location | graphite/api.js |
| Dependencies | Graph, Promise, Query, RDF, Utils |
| Design Pattern | Bridge, Facade |
| Test result | 10 tests, 11 assertions; Total average: 1 493, Average/assertion: 149 |
The API module tries to combine the most powerful modules of Graphite into one module, for easier access to developers new to the framework. The idea is to lower the barrier by combining several modules into one, and built upon their functionality to create new ways of handling the data.
This module differs from the Graphite module in that it acts as a Facade-object for the underlying modules, instead of a simple connection to them. Its signature mirrors in many ways it underlying modules, but adds some methods of its own. In most of the cases though, the mapping are one-to-one, which should make a transition from the API module to the Graph- or Query module easy.
At the heart of the module are the properties g and q, which respectively are instantiations of the Graph- and Query module. These core properties enables the user to cache data from the SW, and query it. The query can be built piece by piece, until it are executed with the execute method.
This module partakes in the Bridge pattern as the Implementor, where the Graphite module works as the Abstraction. It is designed to be easily switched if a system architect wishes to customize the API he wants to serve his team of developers.
6.2 CURIE
| Branch | rdfQuery |
| Location | rdfquery/curie.js |
| Dependencies | URI, Utils |
| Design Pattern | None |
| Test result | 13 tests, 13 assertions; Total average: 60, Average/assertion: 5 |
The CURIE module handles functions regarding CURIEs53, which are quite common when working with SW, as it eases the task of remembering IRIs, in turn helping to reduce typing errors. The functions are split into creating IRIs from CURIEs or vice versa.
CURIE is not written with a SDP in mind, as it is taken from a third party library. It could be argued it is a utilization the Builder pattern, but the strings it returns can hardly be called complex objects.
6.3 Data-type
| Branch | rdfQuery |
| Location | rdfquery/datatype.js |
| Dependencies | URI |
| Design Pattern | Strategy |
| Test result | 12 tests, 22 assertions; Total average: 41, Average/assertion: 2 |
The Data-type module returns a simple function that returns an object representing a data-type. It is used by the RDF module when handling literals. In addition to the callable function there is also a static function valid available, that enables testing whether or not a given value is valid according to a given data-type.
The module uses the Strategy pattern within itself (i.e. no collaboration with other modules). This is done by giving the different data types each a representation with an object containing the properties regex, strip, and value, and in some cases validate. The Context is in this case either the constructor-function, or the static function valid.
6.4 Engine
| Branch | rdfstore-js |
| Location | rdfstore/query-engine/query_engine.js |
| Dependencies | Abstract Query Tree, Callbacks, Query Filters, Query Plan, RDF JS Interface, Loader, Tree Utils, Utils |
| Design Pattern | Builder, Facade |
| Test result | 53 tests, 312 assertions; Total average: 739, Average/assertion: 2 |
The Engine module is a complex module that brings together several submodules, in effect being an implementation of the Facade pattern. Its purpose is to execute queries, and does so by iterations of compiling data, that results in either a formula (as specified in the RDF module), a list of objects with projected variables, or a boolean (depending on the query form, as explained in section 2.1.6.1).
The Builder pattern can be used to understand this module, although it is somewhat hazy. The engine participates as the Director, and RDF JS Interface, Query Filter, and Query Plan all collaborate as Builders. The Product in this case is the result of a query, and it is here it becomes clear that the implementation is not complete, as it is the engine itself that serves the means of getting the Product.
Figure 6.2 shows the dependencies amongst the submodules of the Engine module. Some of the main modules are also represented (i.e. Query Parser, RDF loader, Tree Utils, and Utils), as they have been used by the submodules.
6.4.1 Abstract Query Tree
| Branch | rdfstore-js |
| Location | rdfstore/query-engine/abstract_query_tree.js |
| Dependencies | Query Parser, Tree Utils, Utils |
| Design Pattern | None |
| Test result | 18 tests, 90 assertions; Total average: 182, Average/assertion: 2 |
The Abstract Query Tree module is based on the draft of The SPARQL Algebra54, and does not apply any SDPs as I can see. Again, the code align closely to the Builder pattern, and it should not be to hard to refactor the module. Another pattern that could easily be applied is the Strategy pattern. I will return to this point in the discussion (section 8.1.1.2).
6.4.2 Callbacks
| Branch | rdfstore-js |
| Location | rdfstore/query-engine/callbacks.js |
| Dependencies | Abstract Query Tree, RDF JS Interface, Tree Utils |
| Design Pattern | Builder |
| Test result | 7 tests, 25 assertions; Total average: 101, Average/assertion: 4 |
The Callbacks module is a submodule of the Engine module, and handles the order in which queries should be fired. The module participates in the Builder pattern in collaboration with the RDF JS Interface module, where Callbacks works as the Director, and Interface works as the Builder. It does it with a twist though, as explained in section 6.4.2.
It could also make use of the Observer pattern, which is discussed in section 2.3.8.
6.4.3 Query Filters
| Branch | rdfstore-js |
| Location | rdfstore/query-engine/query_filters.js |
| Dependencies | TreeUtils, Utils |
| Design Pattern | Builder |
| Test result | 15 tests, 29 assertions; Total average: 161, Average/assertion: 6 |
The Query Filters are utility functions for handling queries. It handles aggregation, function calls, and other filter expressions as part of a SPARQL abstract tree. As such, the module acts as a Builder for the engine, which acts as a Director, meaning that the module partakes in the Builder pattern.
The module could also benefit from the use of the Strategy pattern, as many of the filter expressions could be handled as interchangeable objects.
6.4.4 Query Plan
| Branch | rdfstore-js |
| Location | rdfstore/query-engine/query_plan_sync_dpsize.js |
| Dependencies | None |
| Design Pattern | Builder |
| Test result | 1 tests, 12 assertions; Total average: 12, Average/assertion: 1 |
The Query Plan module handles the different ways you can consolidate the different parts of a SPARQL abstract tree. It takes part of the Builder pattern in collaboration with the Engine, Query Filter, and RDF JS Interface, as previously explained.
An adoption of the Strategy pattern would probably clean up the structure, as well as the Composite pattern.
6.4.5 RDF JS Interface
| Branch | rdfstore-js |
| Location | rdfstore/query-engine/rdf_js_interface.js |
| Dependencies | None |
| Design Pattern | Builder |
| Test result | 5 tests, 20 assertions; Total average: 68, Average/assertion: 3 |
The RDF JS Interface module implements the API defined in the document RDF Interfaces55. It outlines many common RDF terms and sports some functions to help creating them. In this we see what resembles an implementation of the Builder pattern (as mentioned in the Engine and Callbacks module).
6.5 Graph
| Branch | Graphite |
| Location | graphite/graph.js |
| Dependencies | Backend, Engine, Lexicon, Promise, RDF, Utils |
| Design Pattern | Strategy |
| Test result | 4 tests, 8 assertions; Total average: 954, Average/assertion: 119 |
The Graph module is the cornerstone of Graphite. It is the abstraction of quadstores, and serves as an access point for all the data processed by the framework. Its signature is somewhat small, but what it powers is the execution of SPARQL-queries. By calling its method execute with a query (be it an instantiation of the module Query, or a plain String) you can add and retrieve data.
To limit the scope of the thesis, I decided to only support a subset of the SPARQL Query Language and SPARQL Update. The subset are:
- Query Forms: ASK, CONSTRUCT, INSERT, LOAD, and SELECT.
- Solution Sequences and Modifiers: ORDER BY.
- Aggregates: GROUP BY.
- Aggregate Algebra: Count, Sum, Avg, Min, and Max.
This means Graphite will only support adding data to the graph, not delete, clear, or update it. Also, subqueries are not supported. This limitation was made to avoid some common problems when dealing with logics in quadstores, as well as limitation imposed by underlying third party code.
The Strategy pattern has been implemented in order to handle the supported forms of queries. It is handled internally, with the function execute fetching a concrete strategy from a map of functions (e.g. executes["Select"] contains the function that handles results from SELECT queries).
An important feature of the Graph module is lazy loading, which secures that the order in which we call resources are handled correctly. This works by making use of the Functional Feature (section 2.2.1.3) combined with the Promise Pattern (section 2.2.6.1). Lazy loading as a design pattern is discussed in section 8.2.2.
The Graphs' and submodules' dependencies are listed in figure 6.3 (Tree Utils are present to show external dependencies).
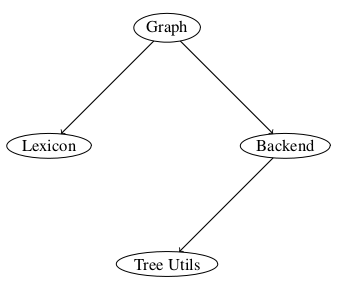
6.5.1 Backend
| Branch | rdfstore-js |
| Location | rdfstore/rdf-persistence/quad_backend.js |
| Dependencies | TreeUtils |
| Design Pattern | None |
| Test result | 2 tests, 57 assertions; Total average: 22, Average/assertion: <1 |
The Backend module handles the storage of RDF-related data in one graph. It makes use of no SDPs.
6.5.2 Lexicon
| Branch | rdfstore-js |
| Location | rdfstore/rdf-persistence/lexicon.js |
| Dependencies | None |
| Design Pattern | None |
| Test result | 2 tests, 9 assertions; Total average: 16, Average/assertion: 2 |
The Lexicon module handles all the graphs that are in play, and resolves terms across graphs. It makes no use of SDPs.
6.6 Graphite
| Branch | Graphite |
| Location | graphite.js |
| Dependencies | API |
| Design Pattern | Bridge |
| Test result | 1 tests, 2 assertions; Total average: 6, Average/assertion: 3 |
The Graphite module is designed to be the main entry point for beginners. It sits at the forefront of the framework (all other modules resides in the folders that are its siblings), and is designed to be easily included into a larger context with an AMD-library. Developers can include this module without knowing anything about it, and start going through tutorials, the documentation, or just play around.
For now it merely returns the API module, but it can be easily extended. One way of doing this is to include the Utils module, which gives the extend-method for objects. By instantiating the different modules whose interface you wish to make highlight, you can combine them into one single object. This could be useful to a system architect who wishes to modify the framework for his project, minimizing the amount of time his developers need to spend to learn the framework. With his alteration he could simply present them with a modified API, that is scissored to their use.
6.7 Loader
| Branch | Graphite |
| Location | graphite/loader.js |
| Dependencies | Proxy, Utils, XHR |
| Design Pattern | Strategy |
| Test result | 1 tests, 1 assertions; Total average: 12, Average/assertion: 12 |
The Loader module fetches resources, and does so depending on what functionality the system supports. All dependent modules prefixed Loader participates in the Strategy Pattern as a ConcreteStrategy.
The dependencies within the submodules of Loader is shown in figure 6.4.
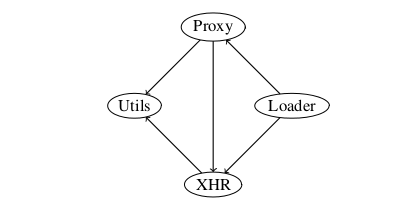
6.7.1 Proxy
| Branch | Graphite |
| Location | graphite/loader/proxy.js |
| Dependencies | Utils, XHR |
| Design Pattern | Bridge, Proxy, Strategy |
| Test result | 2 tests, 4 assertions; Total average: 33, Average/assertion: 8 |
The Proxy module is a participant in the Strategy Pattern as ConcreteStrategy. It was created to bypass the Same Origin Policy (section 2.2.5.1) by using a proxy-server on the same domain. It uses the XHR module to make this connection, and if successful, the service would return the data the framework would otherwise be denied.
This does require a service to be set up on the server, which accepts the formatted query which the Proxy sends. Basically it split the IRI to be loaded into separate parts (as explained in section 2.1.4.2). As part of the framework, this service has been created as an application driven by Node.
6.7.2 XHR
| Branch | Graphite |
| Location | graphite/loader/xhr.js |
| Dependencies | Utils |
| Design Pattern | Bridge, Strategy |
| Test result | 4 tests, 10 assertions; Total average: 68, Average/assertion: 7 |
The XHR module makes use of the XHR2-object available in most modern browsers. It makes use of the Strategy Pattern by participating as a ConcreteStrategy to the Loader module.
6.8 Promise
| Branch | when.js |
| Location | graphite/promise.js |
| Dependencies | None |
| Design Pattern | None |
| Test result | Not available |
The Promise module is an integration of the when.js library. It implements the Promise pattern (section 2.2.6.1), which gives us additional tools to handle asynchronous calls.
6.9 Query
| Branch | Graphite |
| Location | graphite/query.js |
| Dependencies | Loader, Promise, QueryParser, Utils |
| Design Pattern | Builder, Bridge |
| Test result | 51 tests, 52 assertions; Total average: 474, Average/assertion: 9 |
The Query module builds a complex structure that aligns the SPARQL abstract tree, which is used in the Engine module. It partakes in the Builder pattern by being the Director-participant, whereas the Query Parser module (and its submodules) is the Builder-participant.
It also shares another collaboration with the Query Parser module, namely through the Bridge pattern. It serves as an API that can be changed independently of the Query Parser.
6.10 Query Parser
| Branch | Graphite |
| Location | graphite/queryparser.js |
| Dependencies | SPARQL |
| Design Pattern | Builder, Bridge, Strategy |
| Test result | 2 tests, 4 assertions; Total average: 16, Average/assertion: 4 |
The Query Parser module is designed to be extensible, i.e. if there are other ways of serializing the abstraction of a SPARQL query, than it can be extended with this module (e.g. to differ between SPARQL 1.0 and SPARQL 1.1).
The module is designed with the Builder pattern in mind, by participating as the Builder. The Query module is Director, and decides in which order parts of the SPARQL abstract tree is to be added. It further delegates this responsibility to the chosen strategy, e.g. the module that participates as ConcreteStrategy (while the module itself participates as Context).
Figure 6.5 display the dependencies between the modules partaking in the works of the Query Parser.
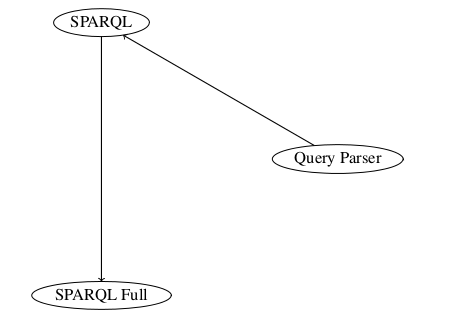
6.10.1 SPARQL
| Branch | Graphite |
| Location | graphite/queryparser/sparql.js |
| Dependencies | SPARQL Full |
| Design Pattern | Builder, Strategy |
| Test result | 36 tests, 56 assertions; Total average: 153, Average/assertion: 3 |
The SPARQL module sports an array of methods that allows building parts of the SPARQL abstract tree. The tree has some constraints concerning how it can be structured, and the module takes care of this.
The module partakes in the Strategy pattern as a concrete strategy. As of now it is the only strategy available, which may make the use of the pattern unnecessary.
The module also participates as a Builder in the Builder pattern. This responsibility is delegated from the Query Parser, which is also the same that acts as Context in the Strategy pattern.
As the module does not support parsing of all the elements in the SPARQL abstract tree, it also imports the use of SPARQL Full module.
6.10.2 SPARQL Full
| Branch | rdfstore-js |
| Location | rdfstore/sparql-parser/sparql_parser.js |
| Dependencies | None |
| Design Pattern | Interpreter |
| Test result | Not available |
The SPARQL Full module is by far the biggest component in Graphite. It is generated by PEG.js, which is a parser generator for JS56. That is also why it is much bigger and more complex than it needs to be. But it does parse a complete SPARQL query, and as I have not been able to create a complete one myself, I have implemented it as part of my framework.
The pattern resembles the Interpreter pattern, as there is a representation of the SPARQL grammar, and I use the module to evaluate its representation into a structured tree of terms from that grammar.
It works as a starting point for manipulating queries, by feeding it with a complete query, and then modify its parts as necessary through the Query module.
6.11 RDF
| Branch | Graphite |
| Location | graphite/rdf.js |
| Dependencies | CURIE, RDF, URI, Utils |
| Design Pattern | Composite, Strategy |
| Test result | 8 tests, 22 assertions; Total average: 44, Average/assertion: 2 |
The RDF module offers a wide arsenal of methods, and creates a common ground for producing objects pertaining to terms in RDF. Many of the methods origins from the N3-parser in rdfstore-js, but has been restructured to promote a consistent API. As such, the method toNT is represented in all objects retrieved from RDF, and it presents the different terms in N3-compliant syntax (e.g. IRI = <(IRI)>).
The module is used by all the parsers, and the Engine is dependent on the toQuads method it appends on all its objects. The objects available through RDF are:
- BlankNode,
- Collection (e.g. a list),
- Empty (i.e. rdfs:nil),
- Formula (i.e. a set of statements),
- Literal,
- Statement, and
- Symbol (e.g. an IRI).
RDF makes use of the Strategy pattern, as all objects listed above have methods toNT and toQuads, meaning there is no need to test for type or feature to know whether or not they can be called.
RDF also makes use of the Composite pattern, as Collection and Formula will call on their leafs when toNT and toQuads are called.
6.12 RDF Loader
| Branch | Graphite |
| Location | graphite/rdfloader.js |
| Dependencies | Loader, RDF Parser, Utils |
| Design Pattern | Facade |
| Test result | Not available |
The RDF Loader module is a very simple module, and does in fact only consist of a single function. The function takes an IRI that can be dereferenced as a graph, the name of that graph, and a function to call when it is loaded. What it passes along is the graph that is been fetched, ready for further processing.
The module acts as facade for the underlying modules that sports a much greater API, and delivers a single, easy-to-use function.
6.13 RDF Parser
| Branch | Graphite |
| Location | graphite/rdfparser.js |
| Dependencies | JSON-LD, RDF JSON, RDF/XML, Turtle, Utils |
| Design Pattern | Strategy |
| Test result | 5 tests, 12 assertions; Total average: 177, Average/assertion: 15 |
The RDF Parser module enables parsing RDF independent of its serialization. For now it needs to be configured by the user to let it know which parser to use, but the goal is to make it detect the serialization on its own.
The module has been designed with the Strategy pattern in mind. By treating all parsers as different strategies to parse RDF, it enables adding and removal additional parsers quite easily (e.g. if we want to be able to parse RDFa). All submodules participates as a ConcreteStrategy.
Another pattern that all submodules use is the Interpreter pattern. The RDF module defines a unified grammar, which they make use of as they evaluate the different serializations.
Figure 6.6 show the dependencies within the RDF Parser modules (RDF, Loader, Promise, URI, and Utils being included to show external dependencies).
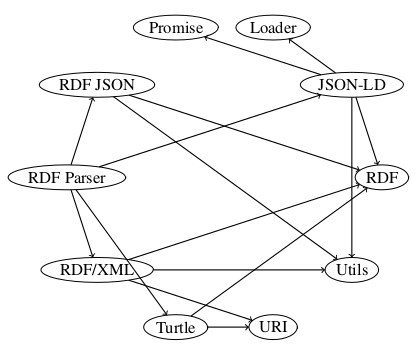
6.13.1 JSON-LD
| Branch | Graphite |
| Location | graphite/rdfparser/jsonld.js |
| Dependencies | Loader, Promise, RDF, Utils |
| Design Pattern | Interpreter, Strategy |
| Test result | 22 tests, 63 assertions; Total average: 272, Average/assertion: 4 |
The JSON-LD module parses JSON-LD into RDF. It also makes use of the Loader and Promise modules as it supports dereferencing URLs that are used in @context.
I decided to implement my own JSON-LD parser instead of reusing the one made available by JSON-LD CG57. I wanted to get a good understanding of JSON-LD, and though creating my own processor could be a good exercise for doing this. When it was complete, it worked well as part of Graphite, it did the work needed, and as such I deemed it unnecessary to integrate even more third party software into the framework.
But as the specification of JSON-LD continue to evolve, my parser will undoubtedly fall behind, and not be able to parse every possible variation. At this point it would probably be preferable to integrate a specialized library, perhaps using the Adapter pattern.
RDF JSON
| Branch | Graphite |
| Location | graphite/rdfparser/rdfjson.js |
| Dependencies | RDF, Utils |
| Design Pattern | Interpreter, Strategy |
| Test result | 8 tests, 9 assertions; Total average: 802, Average/assertion: 89 |
The RDF JSON module parses RDF JSON.
6.13.2 RDF/XML
| Branch | rdfQuery |
| Location | rdfquery/rdfparser/rdfxml.js |
| Dependencies | RDF, URI, Utils |
| Design Pattern | Interpreter, Strategy |
| Test result | 29 tests, 136 assertions; Total average: 1 861, Average/assertion: 14 |
The RDF/XML module is taken from the library rdfQuery, and supports about 60% of the tests given in the official RDF/XML test suite58.
6.13.3 Turtle
| Branch | rdfQuery |
| Location | rdfquery/rdfparser/turtle.js |
| Dependencies | RDF, URI |
| Design Pattern | Interpreter, Strategy |
| Test result | 4 tests, 31 assertions; Total average: 272, Average/assertion: 9 |
The Turtle module originates from rdfQuery, and supports all of the tests given by the Turtle Test Suite59.
6.14 Tree Utils
| Branch | rdfstore-js |
| Location | rdfstore/utils.js |
| Dependencies | B-Tree |
| Design Pattern | None |
| Test result | 5 tests, 35 assertions; Total average: 38, Average/assertion: 1 |
The Tree Utils sports several handy functions used by many of the components originating from rdfstore-js. It also contains an implementation of a B+ tree, which is used by the Engine.
6.14.1 B-Tree
| Branch | rdfstore-js |
| Location | rdfstore/rdf-persistence/in_memory_b_tree.js |
| Dependencies | None |
| Design Pattern | None |
| Test result | 4 tests, 152 assertions; Total average: 53, Average/assertion: <1 |
The B-Tree module is an implementation of a generic B-tree, more specifically an adaptation of one made for C60. It does not make use of any SDPs.
The module could have been integrated into the Tree Utils module, as it is the only making use of B-tree. But as the purpose of this module is so simple and clear, and it may be that I wish to reuse its function, I have decided to let it stay as an independent module.
6.15 URI
| Branch | rdfQuery |
| Location | rdfquery/uri.js |
| Dependencies | Utils |
| Design Pattern | None |
| Test result | 74 tests, 99 assertions; Total average: 267, Average/assertion: 3 |
The URI module originates from the rdfQuery project, and handles many utility-functions used when working with IRI. It applies no SDPs as I can see.
6.16 Utils
| Branch | Underscore.JS |
| Location | graphite/utils.js |
| Dependencies | None |
| Design Pattern | None |
| Test result | 33 tests, 118 assertions; Total average: 142, Average/assertion: 1 |
The Utils module is a collection of utility functions used throughout the framework. Almost all of the functions originate from the Underscore.JS project (section 5.4), and as such it does not apply any SDPs.
When I started integrating code from Underscore.JS to the Utils module (section 6.16), the plan was to keep it at the minimum, only importing what I needed. But throughout the development, more and more code got included (and tests accompanying them), until about 40 of them had become a part of the module. They differ from the original code that they do not implement themselves as shivs, meaning that the function Array.each is implemented as Utils.each, which take a collection as the first parameter.
Chapter 7
The Demo
As part of the development of Graphite my supervisors wanted me to implement an application that showed some of the capabilities of Graphite. I created a music application, that loaded data in different serializations, and that enabled the user to browse this data by search and filtering. It is available as part of the code base61, and on http://folk.uio.no/arnehass/music/.
The demo exists in two versions. Version 1 is built by using the API-module, which works like a facade-object, tying the two most important modules together, namely the Graph- and Query-module. In version 2 the facade is discarded, and the application uses the modules Graph, Query, and Loader directly.
7.1 Structure
The application's data is structured using Turtle and JSON-LD. It uses several vocabularies, as listed below:
- Dublin Core Metadata Initiative (dc: http://purl.org/dc/elements/1.1/),
- Friend of a Friend (foaf: http://xmlns.com/foaf/0.1/), and
- Music Ontology Specification (mo: http://purl.org/ontology/mo/).
In addition, I created my own vocabulary, specific to the demo, prefixed ma and localized as http://example.org/music/v1#. The terms introduced were:
- ma:listensTo: a property stating the relation between a user and a track.
- ma:spotify: a property stating the URI a track has to its instance in Spotify, if any.
- ma:User: a class, used to state a given resource as a user of the application.
The application uses jQuery to manipulate the DOM, and the jQuery plug-in jQuery.template() to handle the templates.
Part 3
Discussion and Conclusion
Chapter 8
Discussion
Chapter 2 describes the pillars which I have built Graphite upon, namely SW (section 2.1, JS (section 2.2), SDP (section 2.3), and TDD (section 2.4). What I have learned while designing the framework can be categorized within the intersections of these pillars (as visualized in figure 8.1), and I have structured the discussion based on those intersections. Finally, at the end of the discussion, I discuss related work.
8.1 SW and JS
Graphite has been a great challenge to implement, many obstacles have been put down, only to face even more. This section describes the challenges regarding the intersection of SW and JS.
8.1.1 Representation of Data
The greatest challenge when working with Graphite have been how to structure the data internally. It was not that I had difficulties representing graphs with tree-based structures, but the fact that different components had different requirements from the structures, making reusability more difficult to achieve.
8.1.1.1 RDF
One problem that seemed to pop up again and again were the different representations of RDF. As I included code from third party libraries, I got at least one representation per library. This is not an unusual problem when using code from other projects, but care should be taken to create a component that can be reused easily by other components.
The document RDF Interfaces addresses this problem by defining "a set of standardized interfaces for working with RDF data in a programming environment" [33]. rdfstore-js actually implements this standard (in the RDF JS Interface module), and the engine uses this as its representation of RDF. As of now, Graphite uses one additional representation, situated in the RDF module. The plan is to integrate this module with the aforementioned implementation of RDF Interfaces.
So how should I implement the functionality concerning representations of terms in RDF? I believe the Decorator pattern (section 2.3.5) is a fitting design for this problem. The reasoning goes that there is an implementation of RDF Interfaces acting as the ConcreteComponent, defining a set of terms suitable when working with RDF. This terms can then be dynamically altered by the ConcreteDecorators, that would be modules altering functionality to meet the ones expected by processors.
8.1.1.2 SPARQL
Representing SPARQL has been easier to work with than RDF, as it has been handled by the components that are all part of the rdfstore-js project. rdfstore-js makes use of the standards defined by W3C, such as the SPARQL Algebra62. The grammar in the algebra maps mostly to the grammar in the SPARQL 1.1 Query Language, and each grammar token is easily represented in JS. This led to the following components:
- The Query module: A bridge to the Query parser, so that we could change/alter the behavior of the Query module independently of the Query Parser.
- The Query Parser module: A simple implementation of the Strategy pattern, allowing me to insert other parsers if needed. As of this writing, it only makes use of the SPARQL parser, but another possibility is to parse jSPARQL, a serialization introduced by the Backplane project (section 8.7.1).
- The SPARQL module: A SPARQL parser with a set of public functions that may parse parts of a query. As I did not have time to create a complete parser, I made use of the parser from rdfstore-js, which is used when there is need to parse a complete query.
This meant that implementing the Query module would simply mean reuse the various representations of tokens, and inserting them wherever appropriate. However, this endeavor proved harder than anticipated, when I discovered that the SPARQL parser produced two distinct structures of patterns.
This forced me to implement logic that tested which of the trees were used as base for the query, and implement different behavior accordingly. This differences probably also has an effect on the engine (as it support both kinds), and I believe the completion of a SPARQL parser independent of the one from rdfstore-js will allow easier creation of reusable components.
8.1.2 Modularity
A feature I surprisingly spent a lot of time on was modularity. One issue was that I needed to support flexibility, since I wanted to return the modules as either:
- A map of functions (i.e. an object without any intrinsic data),
- An instantiated object (i.e. an object with intrinsic data), or
- A function (be it a constructor or not).
In the process I identified five patterns of modular JavaScript patterns, which are explained in section 2.2.8. I decided to go for the AMD pattern, as this was the first pattern supported by the test framework, Buster. This was in spite the fact that neither rdfstore-js nor rdfQuery used this pattern (they use CommonJS Modules and namespaces respectively). That being said, it was not very hard to convert either.
This has led to some consequences though, that I want to highlight here. The first is that the sheer number of modules are not necessarily a good match with asynchronous loading. When I have tested the demo (chapter 7), loading modules takes about one second. This can be remedied, as RequireJS (amongst others) features a code optimizer. In addition to minifying the code (removing whitespace, shortening names, etc) it also throws all modules into one file (by using it on Graphite it turn about 1.8 MB into approximately 350 kB). The optimizer is not to happy about the uses of regular expressions though, and as of yet I cannot use the optimized code. So I do not know how the framework would have fared if being optimized.
A complication of choosing AMD as the module pattern is that most server-side runtime environments do not support it out of the box. This was considered when I chose to go with AMD, as I focused on creating a framework for the web first and foremost. Luckily, there are tools that enable us to run AMD based modules on server-side (e.g. RequireJS has a module for Node63). But that does add complexity and increases the overhead of the framework.
8.1.3 The Engine
The Engine module is probably the most powerful module of all the modules implemented in Graphite, and it is one of the cornerstones of the framework. It is also the most complex and difficult to understand module, and requires further work.
In addition, how it works should be more transparent. I believe one way of doing this to use proven design patterns. I have already mentioned its shaky implementation of the Builder pattern, and how it acts a facade (i.e. using the Facade pattern). But this is probably not a conscious choice, but rather a result of me trying to understand the inner working. I also identified parts of an Observer-pattern, which could be leveraged further.
8.1.3.1 Entailment
Graphite does not support inferring data in any way. When querying, the engine merely looks for patterns, and does no attempt of backward of forward reasoning. I believe that this could be made possible through a plug-in system for the engine. The developer could configure the engine with a specific entailment regime (falling back to simple or no entailment by default), in essence using the Strategy pattern (or maybe the Decorator pattern). This requires a more rigid structure of the engine, i.e. a standard set of functions that plug-in developers could use as hooks.
I believe this task might be too tedious for a web-based application, but could be useful if one were to port the framework to the server-side (further discussed in section 8.1.5), making applications such as SPARQL end-points more powerful.
8.1.3.2 External Service
As of now Graphite only supports working with an internal engine. In case developers want to make use of external processing power, such as to make use of federated queries in SPARQL, a module should be interchangeable with the engine, and as such they should offer the same interface.
8.1.4 Asynchronous Functionality
One important feature I have made use of is the possibility to load resources asynchronously. I have also made it so that the sequence in which queries are inserted are ordered, so querying INSERT DATA before SELECT will ensure that the data is loaded into the graph before the results for the SELECT query are prepared.
In the progress of ensuring this I have been somewhat over-zealous, as I ended up not differing between multiple use of LOAD queries. This means that loading data using the LOAD query will result in a halt in asynchronous loading, i.e. it will in effect be synchronous (waiting for one resource to have been loaded and processed before starting the other). This should be differentiated, so that the framework can load and deserialize representations so that the data is ready for processing when the engine is available.
Another take on this is to make use of the Observer pattern, and implement the result from SPARQL queries as objects that can be notified when there are changes to the dataset. To give an idea of how this might worked, we can see how the framework AngularJS handles data-binding64. They alleviate the need for DOM manipulation on web pages by maintaining a connection between the data presented and the model they are based on. Whenever there is change in the model, that will be reflected in the view. This effect could be useful when working with RDF as well, and would probably be appreciated by developers.
8.1.4.1 XDR
As a warning, I have included this bit on using the XDR object that is available in some of IE browsers. It was designed to handle data-transfer across domains, to overcome SOP (section 2.2.5.1). This is a design it shares with XHR2, but they differ in some important ways.
Most importantly, the developer is not allowed to customize the header sent, i.e. he cannot specify in which format he wishes the data to be replied. Also, GET and POST are the only allowed verbs, and no authentication or cookies are allowed to be sent, meaning modifying through a SPARQL end-point is very difficult. There are other caveats of using XDR65, but these should be enough to get the message: Stay clear of using XDR to request cross-domain resources.
8.1.5 Server-side implementation
I have restrained myself to limit Graphite to support browser environment first and foremost. But I have not let the prospect of supporting server-side environment go completely. By using feature detection we can test which implementation to use (i.e. we have implemented the modules in question using the Strategy pattern), reusing a lot of the code.
The reason I think a server-side implementation should not be thrown off the table is that I think some functionality are best handled server-side, given challenges such as security, resource allocation, data storage, and many more. I believe that supporting both environments would increase the usefulness of the library, as developers would not need to use two different frameworks in case they want to implement an application on both client-side and server-side.
8.1.6 Marketing of SW in JS communities
I have mentioned briefly (in section 2.1.5.6) that JSON-LD CG is skeptical to promote JSON-LD as a serialization of RDF, and by extension promoting as part of the SW standards. This is a legitimate skepticism, as SW has its fair share of skeptics.
One skeptic is Luciano Floridi, who in his publication "Web 2.0 vs. the Semantic Web: A Philosophical Assessment" writes "Regarding the Semantic Web, I argue that it is a clear and well-defined project, which, despite some authoritative views to the contrary, is not a promising reality and will probably fail in the same way AI has failed in the past" [20].
Mike Bergman has another view, making the observation that "the structured Web [...] is a transition phase from the initial document-centric Web to the eventual semantic Web" [4]. He uses the term Structured Web, which I find interesting. I view it as a subpart of what SW is, but much more neutral and applicable in terms of attracting interest from both SW and JS communities.
I tend to agree with JSON-LD CG that SW might be a bit to much to heave upon newcomers. And especially if newcomers come from the JS community, they might not be interested in all the baggage SW offers. They want something that allows them to plug into the increasingly richness of data on WWW. But is also needs to be easy to use, and promote good practices. SW has a lot going on it for the latter part (being part of W3C, having a good process of standardizing), but still have much to desire on the former.
Now, this thesis is not a philosophical study, nor have I any data in social research of JS communities to make any claim of what is the "best way" to go. I simply offer my thought that SW as a whole might be a bit too much for newcomers that are used to working with JS. I believe that emphasis should be put on what your work do, what problems it solves, and maybe tone down the promises SW offers to solve. Keep it simple and pragmatic. That, at least, is my two cents.
8.2 JS and SDP
Applying SDPs in JS can be problematic because of the trivial fact that most design patterns are not designed with JS in mind. And this is the way it should be, as truly good, reusable SDPs can be used independently of any programming language. But one feature that many SDPs assume is contracts, i.e. interfaces. JS does not support this, and the closest emulations are objects that tests the presence of properties.
The absence of interfaces leaves us with a choice: do we want to use emulations or drop them altogether. In this thesis I have chosen to go with the latter, as I already test for a modules' properties with unit tests. The fact that I have implemented this framework on my own is also a factor, as there have been no need for a contracted API in order to collaborate easier with other developers. That is a factor that could change though, and preparations should be made.
I believe that documentation is a viable alternative for communicating a contracted API. Documentation could be spread across multiple documents, depending on the flexibility and social functions needed (e.g. a comment field, to invite others to pitch their ideas). But the continuing life of Graphite is outside the scope of this thesis, and I will not dwell on it further in this text.
8.2.1 Third party libraries
Third party libraries are mentioned in this context as it has been a recurring theme that none of the code I have implemented from third party libraries have been structured with SDPs in mind (or so it seems). Although I am not qualified to offer any in-depth analyzes of why this is the case, I do have some hypotheses that may be of interest.
One reason is the simple fact that design patterns do not seem to be very popular in JS. Reasons for this are entirely speculations on my part, but I believe design patterns are rooted in communities that have not opened their eyes for JS yet. I think this will change though, as JS becomes more popular in the professional communities, especially those that have a degree in CS (i.e. I believe that people having a degree in CS in general are more attuned to the abstract level of solution described by SDPs).
As with many of the topics discussed in this thesis, I also believe SDPs have a case of the egg and the chicken in JS. It is not that popular because there are no great examples of it, and no great examples of it are being developed because it is not popular.
Another reason is the fact that many libraries are very small, and very specific to certain tasks. Especially in the Node community there seems to be a widespread philosophy to keep it simple. In those libraries, there are probably no need for SDP. But in order to alleviate the functions of those libraries, SDP can be a helpful guide in how to structure their collaboration (I hope that Graphite can be a good example of this).
8.2.1.1 Absence of the Adapter pattern
I decided to go head on with the third party code implemented in Graphite, i.e. port the whole code instead of creating modules applying the Adapter pattern. The reasons for this was manifolded:
- Full control of I/O: When implementing the RDF/XML and Turtle parser from rdfQuery, they did not output the data in a way I could easily insert it into the engine.
- Fewer modules: Applying the Adapter pattern would mean implementing an intermediary module, and increase the number of modules. As discussed in section 8.1.2, this may increase the time it takes to load the framework into the application.
- Little to no documentation: Both rdfQuery and rdfstore-js have bad documentation, i.e. either difficult to read and understand or simple missing at all. As such, it felt better to dive into the code, and learn the functionality by porting tests and iteratively adjust it.
8.2.2 Additional SDPs
During the development of Graphite I have stumbled across SDPs beside the ones given in the book Design Patterns. I have restricted myself to referring to this book only, but will mention some of the patterns here, as they have interesting qualities.
Lazy Loading is described by Martin Fowler et.al. as a pattern that "interrupts [the] loading process for a moment, leaving a marker in the object structure so that if the data is needed it can be loaded only when it is used" [21]. It may be implemented as lazy initialization, virtual proxy (used by the Proxy pattern), value holder, and ghost.
Lazy initialization has in fact been used in Graphite, in the Graphite module to be exact. As it handles the manipulation offered by the Query module, it can be described as lazy initialization, first triggered when the method execute is called.
Addy Osmani structures two additional patterns for JS (besides the ones he has adopted from Design Patterns), namely the Constructor pattern and the Module pattern [29]. I have made use of the AMD implementation, which is described as one of multiple implementations available of the latter. But when it comes to the former, I have trouble calling it a design pattern, as they simple describe the different ways to initialize objects in JS. A useful educational pattern for newcomers to JS, but not really helpful when describing the collaboration between multiple components.
8.2.3 Architectural Styles
Roy Fielding has in his dissertation66 a "survey of common architectural styles for network-based application software within a classification framework that evaluates each style according to the architectural properties it would induce if applied to an architecture for a prototypical network-based hypermedia system" [18]. He has evaluated these styles with into 13 properties (Network Performance, User-perceived Performance, Network Efficiency, Scalability, Simplicity, Evolvability, Extensibility, Customizability, Configurability, Reusability, Visibility, Portability, and Reliability) and describes five categories of style (Data-flow, Replication, Hierarchical, Mobile Code, and Peer-to-Peer).
Graphite is network-based, and it could have been interesting to see if any of the styles described by Fielding could have helped communicating the purpose and work of the components. But analyzing them in the context of Fielding's work is outside the scope of this thesis, and I have included this discussion to highlight alternatives to describe the functionalities of the API.
8.2.4 REST
The scope of this thesis being mentioned, a style described by Fielding that is interesting to take an extra look upon is REST. The reason for this is that REST is becoming increasingly popular, also within the JS community67. There is also work done on REST with RDF68.
It could be interesting to either extend or use Graphite as part of an application that implements REST. This could become a platform for automating interaction with data structured in RDF, and leverage is usability to something more than a framework.
8.3 JS and TDD
Buster has been a delight to work with, and been a valuable asset to the development of Graphite. I will recommend all to use TDD as a tool to produce good and solid code, and Buster is a good alternative to use. If the syntax is not your cup of tea, there are other viable options, such as JsTestDriver (backed by Google69) and Jasmine (behavior-driven70).
The definitive gain in using TDD when writing your code is the ease you profit when refactoring code. developing Graphite has involved several rewrites, and failing tests have shown the way to patch things up when something goes wrong. This will also help other developers, if any should join in to collaborate, as they can test that their additions/revisions will not break existing functionality.
There is also the possibility to use test for code coverage (a value that describe to which degree the source code has been tested), with tools such JSCoverage71. There is a project to run code coverage in Buster (buster-coverage72), but I have not been able to apply it.
8.4 SDP and TDD
As already mentioned in section 8.2, applying SDPs in JS projects may prove difficult since JS do not offer contracts to objects. Use of TDD may remedy this fact, as we can test for properties. One way of implementing this is shown in listing 8.2.
function testProperties(obj, properties) {
var prop;
for (prop in properties) {
if (!obj.hasOwnProperty(prop)) throw new Error("Haven't implemented property " + prop);
}
}
// using the Buster framework
buster.testCase("Testing contract", {
"A test that passes": function () {
var myObj = { propA: 42 };
refute.exception(function () {
testProperties(myObj, [ "propA" ]);
});
},
"A test that fails": function () {
var myObj = {};
refute.exception(function () {
testProperties(myObj, [ "propA" ]);
});
}
});
The example could be further elaborated, e.g. by automatically check modules that participates as ConcreteStrategy in the Strategy pattern.
8.5 SW and SDP
Some parts of SW may not gain much by involving SDPs, but I believe they can be effectively used by implementors that wish to create reusable components. The specifications do not say to much of how to implement the collaboration across the standard they propose, and it is this gap that SDP may be used as social contracts.
8.6 SW and TDD
Many of the specifications that take part of SW contains test suites, and TDD is perfectly suited to test the development of implementations trying to support these. In many cases it can help identifying problems within implementations, becoming a common, objective ground for developers to discuss solutions.
8.7 Related Work
During my work on this thesis, I have yet to find academic work that tread the same path as I have outlined. But I have found several libraries that tries to solve the same problem Graphite has undertaken, and that may offer interesting features. Two of them, rdfQuery and rdfstore-js, as I have mentioned several times throughout this thesis, have offered me several reusable components. In this section I will elaborate on their success, independent of their implementation in Graphite.
I have also listed additional libraries of interest, and all in all there are 12 of them. For a complete list of projects I researched in search of related work, see appendix C.
8.7.1 Backplane
Backplane "provides a range of open source components [...] that work together to deliver a fresh approach to web application building" [10]. The owner of this project is Mark Birbeck, who also is the author of the Ubiquity RDFa parser project73, which has been absorbed into Backplane as the RDFa module74.
The project introduces jSPARQL, which sets out to be "an object-based serialization of SPARQL queries" [11]. Although jSPARQL seems to have some interesting properties, I have not had the time to analyze it thoroughly to see its compatibility with full SPARQL. If it is a match, it could be interesting to evolve it further, and make it a part of Graphite.
Backplane is an interesting project in and of itself, but does not seem to have an active development anymore. The last commit was 27th of February 2011, and seems to mark the end of almost one and a half year of development.
8.7.2 Javascript RDF/Turtle Parser
The JavaScript RDF/Turtle Parser is one of many RDF related projects/experiments that Masahide Kanzaki have developed75. It parses Turtle into JSON, is quite compact (547 lines), and may do the job good enough. It has some issues, but should be easy to fix if one would like to take this approach.
8.7.3 JS3
JS3 was first committed 19th of November, 2010 and last updated three days later. It describes itself as "An insane integration of RDF in ECMAScript-262 V5" [32]. It sports an API for manipulating RDF values and to some extent graphs. But it has no parsing, reasoning or querying capacities.
8.7.4 jsonld.js
JSON-LD CG has developed, as part of the work on JSON-LD, several implementations of JSON-LD processors. One of these is jsonld.js, which is available on GH76. Chances are that this processor will feature good code that could be reused in other JS projects.
8.7.5 Jstle
Jstle was first committed 21st of April 2010, and last updated three days later. It describes itself as "Jstle is a terse JavaScript RDF serialization language" [28]. It is a proof of concept, and seems to provide a Turtle-like representation of RDF in JS. But no support for parsing, reasoning or querying.
8.7.6 rdflib.js
rdflib.js seems to be more of a collection of RDF related functionality at the moment than a complete framework for working with RDF with JS. In some cases it also seems like a continuation of rdfQuery, as much of its code resembles a lot (e.g. the use of $rdf as namespace, its dependency on jQuery, and that its structured as a namespace at all). At the moment it features (quoted from the projects webpage [30]):
- Parses RDF/XML, Turtle, N3, and RDFa.
- Serializes RDF/XML, Turtle, and N3.
- Partial SPARQL support.
- Read/Write Linked Data client, using WebDav or SPARQL Update.
- Local API for querying store.
- Can be run server-side with Node.
As mentioned, rdflib.js uses namespaces to structure its code, and this makes it somewhat hard to decouple, not to say reuse. But it does seem to have an active development, and having Tim Berners-Lee contributing is not hurting. Also, although I have not found any source that confirms it, I suspect rdflib.js to be a continuation of the Tabulator project. Read more in section 8.7.12.
rdflib.js is available at GH77.
8.7.7 rdfstore-js
rdfstore-js seems to me to be the most complete project in terms of API and expressive power. It features partial SPARQL support, some parsers, and it uses some standards (full list of features can be read at section 5.3).
The project has some following78, but is mostly a one-man project (Antonio Garrote). This may contribute to the fact that the project has a complete API, and has a overall good architecture. It has a steady development since the first commit was made in 17th of February 2011, and nothing implies this to change anytime soon.
The module pattern implemented is CommonJS modules (section 8.1.2), which makes it a perfect fit for Node, but may also be run in browsers. The project do contain quite messy code at times, which is quite clear in the tests. Also, I suspect the coverage is quite low, as some modules do not have tests at all.
rdfstore-js is, as it declare in its description, "still at the beginning of its development" [23], but I believe this project to have a lot of potential.
8.7.8 rdfQuery
rdfQuery do seem to suffer from inactive development. It has two code bases, one at Google Code79 and one at GitHub80 (the latter mirrors the former, and promises to commit its changes to the original code base). The last change to Google Code was 3rd of September 2011, while the last to GitHub was 21st of June 2011. So it seems that the development has gone somewhat stale.
rdfQuery do seem to be mentioned more often than rdfstore-js, which may be because the fact that its older (the first commit was 17th of October 2008), and may have been the first JS based project that actually got implemented a big code base. That is at least what seems to be the case during my research into this.
The module pattern implemented is namespaces, which makes it somewhat hard to decouple. It also is dependent on jQuery, i.e. increasing the code overhead, which may be of distaste for some developers.
Although rdfQuery do not have an active development any longer, it still has a lot of good code, and some of it is very reusable (as proven in Graphite). And it will probably be useful as a reference for other projects, but it does not seem to have any traction of its own anymore.
8.7.9 Sgvizler
Sgvizler81 is a library in JS "which renders the result of SPARQL SELECT queries into charts or HTML elements" [35]. It is a cool display of how data fetched with SPARQL can be presented on web pages. During the development of Graphite, I wanted to include a demo that made use of Sgvizler, but in the end I did not have time for it.
It is important to note that Sgvizler is not a framework for handling data structured with RDF, but rather a presentation tool. Its scope may be narrow, but it does what it does good.
8.7.10 Simple JavaScript RDF parser and query thingy
The development of the Simple JavaScript RDF parser and query thingy seems to be around 5th of November 2005. Its latest version came out 25th of May 2006, and it does not seem to have any big usage. It supports loading and parsing of RDF/XML-documents, and a crude API for querying.
8.7.11 SPARQL JavaScript Library
The SPARQL JavaScript Library is presented as part of a demonstration of a SPARQL calendar82. It offers some simple handling of SPARQL, which ultimately can be used against a SPARQL endpoint. The code is fairly simple (490 SLOC), have some dependencies, but should be easy to integrate into your own project.
8.7.12 Tabulator
The Tabulator project is a "generic data browser and editor" [40]. It is offered in two ways, as a Firefox extension and as a web application. It does not seem to be developed any further, but its code base (whole 120 files of JS) offers a lot of functionality, and it seems that some of it is continued in rdflib.js (such as the files jquery.uri.js and jquery.xmlns.js). Tim Berners-Lee was also involved in the Tabulator project, so this may not come as a big surprise.
Chapter 9
Conclusion
As part of this thesis I implemented Graphite, a framework that offers an API in JS for accessing SW. I used parts of other projects and sewed it all together to one, functional prototype. It is not complete, further work is required, but it stands as an example of how a framework could look and behave.
Creating a framework offers many challenges. How should the code be structured? If you wish to modularize your functionality, how should you divide it? Is the increased overhead of modularity justifiable? What are the appropriate ways to make your components collaborate? All these questions, and more, have found their answers in Graphite.
Graphite is an example of how a framework could look like. This time I emphasize could, because this is merely one of many possible implementations that can be made. Implementations that have other answers to the challenges they faced. And this fact reveals one of the conclusions this thesis offers: Components should be created with reusability in mind. This is definitely the case with framework configured to handle resources in SW.
SW is like a big cake of standards. Each slice contains a mixture of its ingredients, and even if you were to split them into separate parts, like glaze, it is still best consumed together. The metaphor can also be used to explain why we need multiple parts to make it all work (i.e. to make the cake taste good); some parts (e.g. sodium and flour), is just not good by itself.
SW consists of many standards, and to mix them all together takes some planning. In this thesis I have used SDPs as guides to map participants and collaborations. This proved to be somewhat complex, as there were two factors working against us: One is that JS does not support interfaces, which is used thoroughly in the classic descriptions. Another is that none of the third party code I implemented seemed to have SDPs in mind when implemented, which meant that I had to restructure some code to fit my purpose.
Restructuring is a cumbersome process, which introduces many opportunities to break existing functionality. I used TDD throughout the development to prevent this, which proved effective. It also allowed me to move code across modules, to restructure the very purpose of modules. Patterns have guided me in this process, and I believe it to be an effective route.
The construction of Graphite has been an important part of the realizations revealed in this thesis. If anything, it has shown that the magnitude of SW requires many components to collaborate. It also shows that one framework probably will not "get" it all. So to ease the work of developers, both those constructing the frameworks and those using them, care should be made to make components reusable. And to guide how those components should function and be structured, we use standards, to tap into the work of many, bright people before us.
9.1 Further Work
Work that may be derived from this thesis is naturally concentrated on improving the code of Graphite. I have mentioned aspects that could be interesting to look into, such as using the architectural styles introduced by Roy Fielding to analyze frameworks in JS.
But the most interesting work would probably involve improvement of the implementation. Some suggestions of aspects to look into are:
- The engine needs to be decoupled and structured more clearly with SDPs in mind. This would open the code for other developers, and enable them to introduce other algorithms that are more effective. This is particularly important if we want to introduce inferring capabilities.
- The SPARQL parser needs to be complete, and the engine needs to be able to process all possible variances. Until that is complete, the framework can not make full use of the querying possibilities of SW.
- A module parsing RDFa would be useful, especially if browsers should loosen up on SOP. Also, the RDF/XML parser needs to be completed, and the JSON-LD parser probably needs to be updated (or replaced with another altogether) as the specification becomes a recommendation by W3C.
- Storage in browsers could be an interesting functionality to look into, as off-line capacities may become a trend. This could be used as part of caches, and thereby increase the speed of applications that are used multiple times and which do not need to fetch data from an external resource every time.
- The engine module should be one alternative of many; The developer should be able to configure the system to use an external SPARQL endpoint as query processor. Graphite supports this to some degree, but as of now it would be more like a hack.
- Graphite should be able to be run server-side. As part of this, serializers should be implemented, so that the service can serve RDF in any format requested.
- Are there alternatives to representing RDF internally? Both RDF JSON and JSON-LD are JSON-based serializations of RDF, maybe they are viable alternatives.
- Serializes: If you want to make your code available for server-side implementations, than you should probably support a couple of serializers, as developers setting up a server probably want to serve serialized RDF from your store.
References
- [1]
- Christopher Alexander, Sara Ishikawa, Murray Silverstein, Max Jacobsen, Ingrid Fiksdahl-King, and Shlomo Angel. A Pattern Language. Oxford University Press, 1977.
- [2]
- Dave Beckett. RDF/XML Syntax Specification (Revised). http://www.w3.org/TR/rdf-syntax-grammar/, February 2004. [Online, retrieved 11-July-2012].
- [3]
- David Beckett and Tim Berners-Lee. Turtle - Terse RDF Triple Language. http://www.w3.org/TeamSubmission/turtle/, March 2011. [Online, retrieved 15-July-2012].
- [4]
- Mike Bergman. More Structure, More Terminology and (hopefully) More Clarity AI3:::Adaptive Information. http://www.mkbergman.com/391/more-structure-more-terminology-and-hopefully-more-clarity/. [Online, retrieved 7-Aug-2012].
- [5]
- Tim Berners-Lee. Semantic Web Road map. http://www.w3.org/DesignIssues/Semantic.html, November 1998. [Online, retrieved 10-July-2012].
- [6]
- Tim Berners-Lee. Notation 3 Logic. http://www.w3.org/DesignIssues/Notation3.html, August 2005. [Online: Accessed 20-July-2012].
- [7]
- Tim Berners-Lee. Linked Data. http://www.w3.org/DesignIssues/LinkedData.html, June 2009. [Online, retrieved 14-July-2012].
- [8]
- Tim Berners-Lee and Dan Connolly. Notation3 (N3): A readable RDF syntax. http://www.w3.org/TeamSubmission/n3/, 2011. [Online, retrieved 15-July-2012].
- [9]
- Tim Berners-Lee, James Hendler, and Ora Lassila. The semantic web. Scientific American, 284(5):34-43, May 2001.
- [10]
- Mark Birbeck. backplanejs - A JavaScript library that provides cross-browser XForms, RDFa, and SMIL support. - Google Project Hosting. https://code.google.com/p/backplanejs/. [Online, retrieved 7-Aug-2012].
- [11]
- Mark Birbeck. TutorialUsingJsparql - ubiquity-rdfa - This tutorial shows how to use jSPARQL, a JSON serialisation of SPARQL. - The Ubiquity RDFa parser project - Google Project Hosting. http://code.google.com/p/ubiquity-rdfa/wiki/TutorialUsingJsparql. [Online, retrieved 7-Aug-2012].
- [12]
- Christian Bizer, Tom Heath, and Tim Berners-Lee. Linked Data - The Story So Far. http://tomheath.com/papers/bizer-heath-berners-lee-ijswis-linked-data.pdf. [Online, retrieved 14-July-2012].
- [13]
- Dan Brickley and R.V. Guha. RDF Vocabulary Description Language 1.0: RDF Schema. http://www.w3.org/TR/rdf-schema/, February 2004. [Online, retrieved 11-July-2012].
- [14]
- Brian Cavalier. cujojs/when. https://github.com/cujojs/when. [Online, retrieved 7-Aug-2012].
- [15]
- Douglas Crockford. JavaScript: The World's Most Misunderstood Programming Language. http://www.crockford.com/javascript/javascript.html, January 2001. [Online, retrieved 10-July-2012].
- [16]
- Douglas Crockford. The application/json Media Type for JavaScript Object Notation (JSON). http://www.ietf.org/rfc/rfc4627.txt, July 2006. [Online, retrieved 19-July-2012].
- [17]
- Ecma International. ECMAScript Language Specification, 2011. [Online, retrieved 13-July-2012].
- [18]
- Roy Thomas Fielding. Architectural Styles and the Design of Network-based Software Architectures. PhD thesis, University of California, 2000. [Available online http://www.ics.uci.edu/~fielding/pubs/dissertation/net_arch_styles.htm, retrieved 27-July-2012].
- [19]
- David Flanagan. JavaScript: The Definitive Guide, Sixth Edition. O'Reilly Media, Inc., 2011.
- [20]
- Luciano Floridi. Web 2.0 vs. the semantic web: A philosophical assessment. Episteme, 6(1):25-37, 2009.
- [21]
- Martin Fowler, David Rice, Matthew Foemmel, Edward Hieatt, Robert Mee, and Randy Stafford. Patterns of Enterprise Application Architecture. Addison Wesley, 2002.
- [22]
- Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. Design Patterns - Elements of Reusable Object-Oriented Software. Addison-Wesley, 1994.
- [23]
- Antonio Garrote. antoniogarrote/rdfstore-js. https://github.com/antoniogarrote/rdfstore-js/. [Online, retrieved 7-Aug-2012].
- [24]
- John Hebeler, Matthew Fisher, Ryan Blace, and Andrew Perez-Lopez. Semantic Web Programming. Wiley Publishing, Inc., 2009.
- [25]
- Pascal Hitzler, Markus Krötsch, and Sebastian Rudolph. Foundations of Semantic Web. Chapman & Hall/CRC, 2010.
- [26]
- Graham Klyne and Jeremy J. Carroll. Resource Description Framework (RDF): Concepts and Abstract Syntax. http://www.w3.org/TR/rdf-concepts/, February 2004. [Online, retrieved 11-July-2012].
- [27]
- Paul Krill. JavaScript creator ponders past, future. http://www.infoworld.com/print/39704, June 2008. [Online, retrieved 10-July-2012].
- [28]
- Dan Newcome. dnewcome/jstle - GitHub. https://github.com/dnewcome/jstle, April 2010. [Online, retreieved 7-Aug-2012].
- [29]
- Addy Osmani. Learning JavaScript Design Patterns. O'Reilly Media, Inc., 2012. [Online, retrieved 19-July-2012; Available as free e-book].
- [30]
- rdflib.js Team. linkeddata/rdflib.js. https://github.com/linkeddata/rdflib.js. [Online, retreieved 7-Aug-2012].
- [31]
- Dirk Riehle. Framework Design: A Role Modeling Approach. PhD thesis, Eidgenössische Technische Hochschule Zürich, 2000. [Available online http://dirkriehle.com/computer-science/research/dissertation/, retrieved 30-July-2012].
- [32]
- Nathan Rixham. webr3/js3 - GitHub. https://github.com/webr3/js3, November 2010. [Online, retreieved 7-Aug-2012].
- [33]
- Nathan Rixham, Manu Sporny, Mark Birbeck, Ivan Herman, and Benjamin Adrian. RDF Interfaces 1.0. http://www.w3.org/TR/2011/WD-rdf-interfaces-20110510/, May 2011. [Online, retreieved 7-Aug-2012].
- [34]
- John Godfrey Saxe. The Poems of John Godfrey Saxe. Houghton, Mifflin and Company, 1881.
- [35]
- Martin G. Skjæveland. Sgvizler: A javascript wrapper for easy visualization of sparql result sets. ESWC 2012, 2012. Is yet to be published, but is to be a demo paper in the workshop/poster/demo proceedings of ESCW 2012.
- [36]
- Buster Team. Buster.JS overview. http://busterjs.org/docs/overview/. [Online, retrieved 7-Aug-2012].
- [37]
- Git Team. Git - Reference. http://git-scm.com/docs. [Online, retrieved 7-Aug-2012].
- [38]
- Node Team. node.js. http://nodejs.org/. [Online, retrieved 7-Aug-2012].
- [39]
- RequireJS Team. RequireJS. http://requirejs.org/. [Online, retrieved 7-Aug-2012].
- [40]
- Tabulator Team. Tabulator: Generic data browser. http://www.w3.org/2005/ajar/tab. [Online, retrieved 7-Aug-2012].
- [41]
- Underscore Team. Underscore.js. http://underscorejs.org/. [Online, retrieved 7-Aug-2012].
- [42]
- Jeni Tennison. rdfquery - RDF processing in your browser - Google Project Hosting. http://code.google.com/p/rdfquery/, June 2011. [Online, retrieved 7-Aug-2012].
- [43]
- Architecture of the World Wide Web, Volume One. http://www.w3.org/TR/webarch/, 2004. [Online, retrieved 14-July-2012].
- [44]
- World Wide Web Consortium (W3C). OWL Web Ontology Language Overview, 2004. [Online, retrieved 13-July-2012].
- [45]
- RDF Test Cases. http://www.w3.org/TR/rdf-testcases/, February 2004. [Online, retrieved 15-July-2012].
- [46]
- World Wide Web Consortium (W3C). OWL 2 Web Ontology Language Document Overview, 2009. [Online, retrieved 14-July-2012].
- [47]
- World Wide Web Consortium (W3C). OWL 2 Web Ontology Language Profiles, 2009. [Online, retrieved 14-July-2012].
- [48]
- World Wide Web Consortium (W3C). SPARQL 1.1 Query Language, May 2011. [Online, retrieved 16-July-2012].
- [49]
- World Wide Web Consortium (W3C). JSON-LD Syntax 1.0, 2012. [Online, retrieved 15-July-2012].
- [50]
- Semantic Web - W3C. http://www.w3.org/standards/semanticweb/, July 2012. [Online, retrieved 10-July-2012].
Part 4
Appendices
Appendix 1
Code Base
As the code base for Graphite is rather large (approximately 36 000 SLOC, or between 500 and 1 000 pages, depending on the format you print it in), I have decided to just refer to the repository at GH.
The complete framework, with all tests and demos, is available at https://github.com/megoth/graphitejs.
Appendix 2
Test Results
Table B.1 shows the latest results from running test runs on all the modules included in Graphite. There are 430 tests altogether, with a total of 1 413 assertions. The numbers given for Average per testruns and Average per assertion are in milliseconds. The former gives the average of ten sequent runs, while the latter gives the average time per assertion.
| Module | Tests | # assertions | Avg/assertion | Avg/testrun |
|---|---|---|---|---|
| API | 9 | 10 | 149 | 1493 |
| CURIE | 13 | 13 | 5 | 60 |
| Datatype | 12 | 22 | 2 | 41 |
| Engine | 53 | 312 | 2 | 739 |
| Abstract Query Tree | 18 | 90 | 2 | 182 |
| Callbacks | 7 | 25 | 4 | 101 |
| Query Filters | 15 | 29 | 6 | 161 |
| Query Plan | 1 | 12 | 1 | 12 |
| RDF JS Interface | 5 | 20 | 3 | 68 |
| Graph | 4 | 8 | 119 | 954 |
| Backend | 2 | 57 | 0 | 22 |
| Lexicon | 2 | 9 | 2 | 16 |
| Graphite | 1 | 2 | 3 | 6 |
| Loader | 1 | 1 | 12 | 12 |
| Proxy | 2 | 4 | 8 | 33 |
| XHR | 4 | 10 | 7 | 68 |
| Query | 51 | 52 | 9 | 474 |
| Query Parser | 2 | 4 | 4 | 16 |
| SPARQL | 36 | 56 | 3 | 153 |
| RDF | 8 | 22 | 2 | 44 |
| RDF Parser | 5 | 12 | 15 | 177 |
| JSON-LD | 22 | 63 | 4 | 272 |
| RDF JSON | 8 | 9 | 89 | 802 |
| RDF/XML | 29 | 136 | 14 | 1861 |
| Turtle | 4 | 31 | 9 | 272 |
| Tree Utils | 5 | 35 | 1 | 38 |
| B-Tree | 4 | 152 | <1 | 53 |
| URI | 74 | 99 | 3 | 267 |
| Utils | 33 | 118 | 1 | 142 |
Appendix 3
Findings of Related Work
Table C.1 shows a list of projects I have examined as part of this thesis. A total of 114 projects were found, mostly through the service AI3 Sweet Tools83, which has a comprehensive listing of Semantic Web related tools (the search returned 94 results when querying "javascript"). I have also included projects listed at W3Cs wiki page on Javascript84, while the last few are the result of Google search and friendly tips.
The projects are analyzed with four categories: Available (Av), Semantic Web (SW), JavaScript (JS), and Easy Reusable (ER). The projects are either true or false to each of the categories (represented by 1 or 0 in the table, respectively). Also, the categories are sorted, from left to right, and one category that results in false on one category, will not be analyzed into the following category. If a project is analyzed as true to all categories, it is labeled as interesting, and was taken into further analyzing. Section 8.7 lists all these projects.
The category Available regards a project as true if the code of that project is dereferenceable and open source.
The category Semantic Web regards whether a project actually had any technologies related to SW. Many of the tools listed by AI3 were annotation tools, and did not have anything to do with the semantic technologies curated by W3C.
The category JavaScript checked whether the project had any code of interest in JS.
Finally, the category Easy Reusable checks whether or not the JS included in the project are easily reusable for the purpose of this thesis. It is more informal than the other categories, in that it was - in the end - my gut feeling of a projects code that regarded it as easy to reuse or not. Factors considered were purpose, flexible, overall structure, handling of data, and originality.
| Name | Av | SW | JS | ER |
|---|---|---|---|---|
| Acre | 1 | 0 | ||
| ALOE | 0 | |||
| Annozilla | 1 | 0 | ||
| Anzo Suite | 0 | |||
| backplanejs | 1 | 1 | 1 | 1 |
| blueorganizer | 0 | |||
| Callimachus | 1 | 1 | 0 | |
| chickenfoot | 1 | 0 | ||
| Chimaera | 0 | |||
| Clipmarks | 0 | |||
| Clustybar | 0 | |||
| Code Mirror | 1 | 0 | ||
| Collex | 0 | |||
| Crowbar | 1 | 0 | ||
| Cuebee | 0 | |||
| DataMashups | 0 | |||
| DBpedia Spotlight | 1 | 1 | 0 | |
| Disco | 1 | 1 | 0 | |
| Dojo.data | 1 | 0 | ||
| Dublin Core Viewer | 0 | |||
| ED (Entity Describer) | 0 | |||
| Euler | 0 | |||
| EulerMOZ | 1 | 1 | 0 | |
| Exhibit | 1 | 0 | ||
| Exparql | 0 | |||
| Finnish Ontology Library Service ONKI | 1 | 1 | 1 | 0 |
| Flint SPARQL Editor | 1 | 1 | 1 | 0 |
| FOAF-o-matic | 1 | 1 | 0 | |
| Fuzz | 0 | |||
| GeoURL | 0 | |||
| Grazr | 0 | |||
| GrOWL | 0 | |||
| Hercules | 0 | |||
| Hunter Gatherer | 0 | |||
| HyperBK | 0 | |||
| HyperScope | 0 | |||
| iServe Browser | 1 | 1 | 0 | |
| JavaScript RDF/Turtle parser | 1 | 1 | 1 | 1 |
| Jiqs4OWL | 0 | |||
| jOWL | 1 | 1 | 1 | 0 |
| JS3 | 1 | 1 | 1 | 1 |
| jsonld.js | 1 | 1 | 1 | 1 |
| JSTLE | 1 | 1 | 1 | 1 |
| LAPIS | 1 | 0 | ||
| Linked Data Mapper | 1 | 0 | ||
| Live Clipboard | 0 | |||
| Marmite | 0 | |||
| MOAW | 0 | |||
| mSpace | 1 | 0 | ||
| Nokia Semantic Web Server | 1 | 1 | 0 | |
| OAI Repository Explorer | 0 | |||
| Ocelot | 0 | |||
| One Click Annotator | 1 | 1 | 0 | |
| Open Anzo | 1 | 1 | 0 | |
| OpenLink AJAX Toolkit (OAT) | 1 | 1 | 1 | 0 |
| OpenLink Data Explorer (ODE) | 1 | 1 | 1 | 0 |
| OpenLink Virtuoso | 1 | 1 | 0 | |
| OpenRecord | 1 | 0 | ||
| Operator | 0 | |||
| OPML Reader | 0 | |||
| OPML Support | 0 | |||
| OwlSight | 0 | |||
| Piggy Bank | 1 | 1 | 0 | |
| Pipes | 0 | |||
| PoolParty | 0 | |||
| Potluck | 0 | |||
| pushback | 1 | 1 | 1 | 0 |
| rCache | 0 | |||
| RDF Viewer | 0 | |||
| RDFa Developer | 1 | 1 | 0 | |
| RDFaCE | 1 | 1 | 1 | 0 |
| RDFaPI-JS | 1 | 1 | 1 | 0 |
| rdflib.js | 1 | 1 | 1 | 1 |
| rdfQuery | 1 | 1 | 1 | 1 |
| rdfstore-js | 1 | 1 | 1 | 1 |
| Rhizomer | 1 | 1 | 1 | 0 |
| Sage | 0 | |||
| Sahi | 0 | |||
| Scaffold | 0 | |||
| Scooner | 0 | |||
| ScrapBook | 1 | 0 | ||
| Semantic Radar | 0 | |||
| Semantic Turkey | 1 | 1 | 0 | |
| Semantic Web Pipes | 1 | 1 | 0 | |
| semanticgraph | 1 | 1 | 1 | 0 |
| SemanticSTEP Viewer | 0 | |||
| SemClip | 0 | |||
| sgvizler | 1 | 1 | 1 | 1 |
| Sifter | 1 | 1 | 0 | |
| Sig.ma | 1 | 1 | 0 | |
| Simple javascript RDF Parser and query thingy | 1 | 1 | 1 | 1 |
| SKOS_WS | 0 | |||
| Solvent | 1 | 1 | 0 | |
| Sparallax | 0 | |||
| Spark | 1 | 1 | 0 | |
| SPARQL JavaScript Library | 1 | 1 | 1 | 1 |
| sparqlPuSH | 1 | 1 | 0 | |
| Strata | 0 | |||
| structOntology | 1 | 1 | 0 | |
| sw-widgets | 0 | |||
| Sweet Tools | 0 | |||
| Swipe | 0 | |||
| Sztakipedia | 0 | |||
| Tabulator | 1 | 1 | 1 | 1 |
| Timeline | 1 | 1 | 1 | 0 |
| Twarql: Twitter feeds through SPARQL | 0 | |||
| Ubiquity-RDFa | 0 | |||
| Visualisations for the CS AKTive Portal | 0 | |||
| VIVID | 0 | |||
| Web Clipboard | 0 | |||
| Wikimeta | 0 | |||
| Wrangler | 0 | |||
| WSO2 Mashup Server | 0 | |||
| Zotero | 0 |
Footnotes:
- 1This might be wrong: http://www.w3.org/TR/2004/REC-owl-features-20040210/\#s1.3 states that OWL 1 has three sublanguages, while http://www.w3.org/TR/2009/REC-owl2-new-features-20091027/\#Backward_Compatibility claims that it only has one. But for the purposes of this thesis, I work with three sublanguages.
- 2http://www.w3.org/DesignIssues/LinkedData.html
- 3Examples of this are platforms such as the UK initiative to open governmental data (http://data.gov.uk/), US' approach of the same (http://www.data.gov/), and Norway's parliament opening of its databases through Stortingets datatjeneste (http://data.stortinget.no/). You also have other non-governmental organizations, such as PMOs.
- 4Well, as of 19th of September 2011, when the diagram was last updated.
- 5Therefore, strictly speaking, it does not matter whether I use URIs or IRIs in this thesis, as I do not use any non-ASCII signs in any of the IRI I present.
- 6http://docs.api.talis.com/platform-api/output-types/rdf-json
- 7http://www.w3.org/TR/json-ld-syntax/
- 8http://json-ld.org/, http://www.w3.org/community/json-ld/
- 9http://www.w3.org/blog/SW/2011/09/13/the-state-of-rdf-and-json/
- 10Topic: Formal Definition of Linked Data at http://json-ld.org/minutes/2011-07-04/
- 11http://www.w3.org/TR/rdfa-primer/
- 12http://www.w3.org/TR/rdfa-core/
- 13http://www.w3.org/TR/rdfa-lite/
- 14http://www.w3.org/TR/xhtml-rdfa/
- 15http://www.w3.org/TR/rdfa-in-html/
- 16The SPARQL 1.1 specification numbers almost 100 pages as of this writing
- 17http://www.w3.org/TR/rdf-mt/
- 18http://www.w3.org/TR/owl2-direct-semantics/
- 19http://www.crockford.com/javascript/javascript.html
- 20Design issues in JS has given rise to many frustrating moments, creating momentum for websites such as http://wtfjs.com/, which delivers examples of "weird code".
- 21In this regard, http://dailyjs.com/ offers a variety of good resources for learning JS, specifically its articles tagged with #beginner (http://dailyjs.com/tags.html\#beginner).
- 22Despite the slow pace of browser-update in some communities, e.g. usage of IE6 in China, lousy implementations is a thing that is becoming a thing of the past.
- 23Which include, in the authors view:
- JavaScript: The Definitive Guide, 6th edition, by David Flanagan (O'Reilly Media).
- JavaScript: The Good Parts, by Douglas Crockford (O'Reilly Media).
- 24Notably, in Norway you have Web Rebels (http://webrebels.org/), and JS has its own session on NDC, with somewhat above 10% of the talks concerning JS.
- 25One example being jQuery, which is shipped with Microsoft's Visual Studio, another being AngularJS, which is an MIT-licensed MVC framework developed by Google.
- 26That being said, percentage-wise it is probable that JS is still written by more amateurs than professional developers. This is not a bad thing though, as it expresses the power of adaptation that JS features, and may be a gateway for developers-to-be. Also, lets not forget that the word amateur means "lover of", and love of computer technologies is something to be embraced.
- 27A lot can be said about trust on the web, but that is not the purpose of this thesis.
- 28http://code.google.com/p/browsersec/wiki/Part2\#Same-origin_policy
- 29http://www.w3.org/TR/CSP/
- 30http://www.w3.org/TR/cors/
- 31http://www.commonjs.org/
- 32http://wiki.commonjs.org/wiki/Promises/A
- 33http://wiki.commonjs.org/wiki/Modules/Async/A
- 34Although some environments, such as Node, loads the dependencies synchronously.
- 35http://code.google.com/p/traceur-compiler/
- 36https://code.google.com/p/esprima/
- 37http://c2.com/doc/oopsla87.html
- 38That being said, I have described how you could implement a function that tests properties in section 8.4.
- 39http://addyosmani.com/resources/essentialjsdesignpatterns/book/\#decoratorpatternjavascript
- 40Inspired by the example given by Mike Pennisi in his blog post at http://weblog.bocoup.com/the-strategy-pattern-in-javascript/
- 41https://github.com/busterjs/buster
- 42https://github.com/joyent/node
- 43http://www.mozilla.org/rhino/
- 44For complete list, see the documentation at http://git-scm.com/docs
- 45https://github.com/about/
- 46http://www.jetbrains.com/webstorm/features/index.html
- 47http://code.google.com/p/rdfquery/
- 48https://github.com/alohaeditor/rdfQuery
- 49http://www.w3.org/TR/rdf-interfaces/
- 50http://www.w3.org/TR/rdf-sparql-protocol/
- 51https://github.com/antoniogarrote/rdfstore-js/
- 52https://github.com/cujojs/when
- 53http://www.w3.org/TR/curie/
- 54http://www.w3.org/2001/sw/DataAccess/rq23/rq24-algebra.html
- 55http://www.w3.org/TR/rdf-interfaces/
- 56http://pegjs.majda.cz/
- 57https://github.com/digitalbazaar/jsonld.js
- 58http://www.w3.org/TR/rdf-testcases/
- 59http://www.w3.org/TeamSubmission/turtle/tests/
- 60http://www.gossamer-threads.com/lists/linux/kernel/667935
- 61https://github.com/megoth/graphitejs/tree/master/demo-music
- 62http://www.w3.org/2001/sw/DataAccess/rq23/rq24-algebra.html
- 63http://requirejs.org/docs/node.html
- 64This pattern are also available at other frameworks, such as Backbone (http://backbonejs.org/)
- 65A good list is available at http://blogs.msdn.com/b/ieinternals/archive/2010/05/13/xdomainrequest-restrictions-limitations-and-workarounds.aspx.
- 66Freely available at http://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm.
- 67There are several successful frameworks implementing a RESTful architecture, such as AngularJS (http://angularjs.org/), Ext JS (http://docs.sencha.com/ext-js/4-1/\#!/api/Ext.data.proxy.Rest), and qooxdoo (http://manual.qooxdoo.org/current/pages/communication/rest.html).
- 68My own supervisor, Kjetil Kjernsmo, has contributed to this with his paper "The necessity of hypermedia RDF and an approach to achieve it" (available at http://folk.uio.no/kjekje/2012/hypermedia-rdf.pdf).
- 69http://code.google.com/p/js-test-driver/
- 70http://pivotal.github.com/jasmine/
- 71http://siliconforks.com/jscoverage/
- 72http://gitorious.org/buster-coverage
- 73https://code.google.com/p/ubiquity-rdfa/
- 74http://code.google.com/p/backplanejs/wiki/RdfaModule
- 75http://www.kanzaki.com/works/
- 76https://github.com/digitalbazaar/jsonld.js
- 77https://github.com/linkeddata/rdflib.js
- 78At the time of this writing, it had been forked 12 times, and had 126 watchers.
- 79http://code.google.com/p/rdfquery/
- 80https://github.com/alohaeditor/rdfQuery
- 81Available at http://code.google.com/p/sgvizler/.
- 82http://www.thefigtrees.net/lee/blog/2006/04/sparql_calendar_demo_a_sparql.html
- 83http://www.mkbergman.com/sweet-tools/
- 84http://www.w3.org/2001/sw/wiki/Javascript